
Introducing Evervault Page Protection: Securing payment pages from JavaScript attacks
Secure your payment pages against script and security header attacks while complying with PCI DSS 4.0 requirements, 6.4.3, and 11.6.1.
By Shane Curran
Shane Curran
Shane Curran

Engineer
In this blog post, we discuss how we created an abstraction layer so that users can build apps without needing to make custom changes to suit an enclave environment. Nitro Enclaves are designed with no networking by default, and it’s up to the user to create their own systems for routing traffic in and out of the enclave. This can be a laborious process that involves managing traffic over VSOCK through a series of proxies. Our control and data plane layer allows any simple TCP app to get running on an enclave in less than 15 minutes.
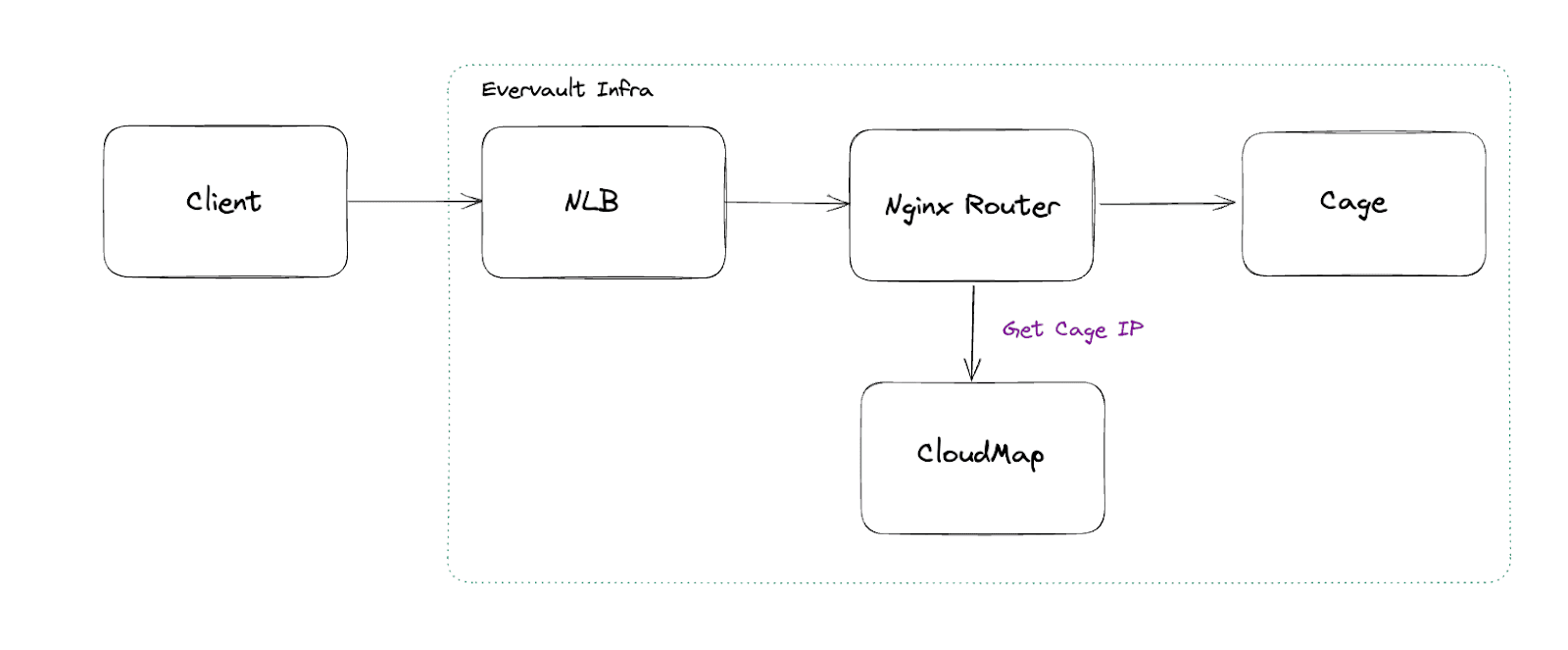
As we mentioned in the last post on provisioning, TLS termination must occur within the enclave so that traffic is never unencrypted on Evervault’s networking infrastructure. To support this, we use a Network Load Balancer (NLB) and Server Name Indication (SNI) to route traffic without terminating TLS.
Ingress requests hit an NLB that sits in front of an Nginx routing layer that will route traffic to a specific Cage. Cages are assigned a hostname based on the following structure: `{cage_name}.{app_uuid}.cages.evervault.com`, and the internal IP of the service is registered in Cloudmap on startup. When Nginx receives a request, the SNI will be parsed to find the Cage name and app uuid and the request will be routed to the Cage based on the IP obtained from Cloudmap.
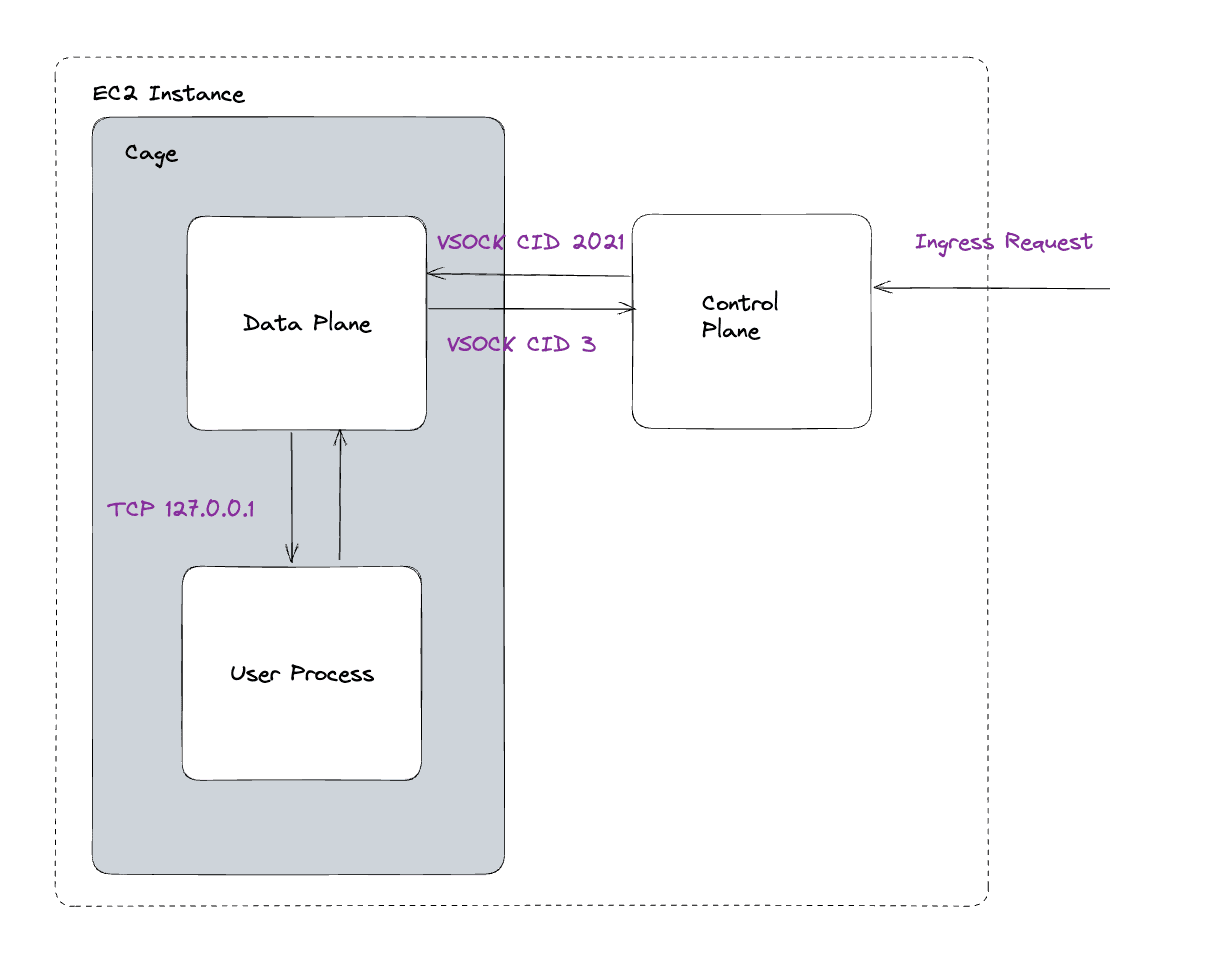
The only channel for communication between an enclave and parent instance is over VSOCK, an address family that facilitates traffic between a VM and a host machine. It has poor language support and is generally harder to grasp than TCP as it’s less commonly used by developers. Knowing that dealing directly with VSOCK can be challenging, we developed a data plane layer to abstract away the difficulty in dealing with VSOCK connections so that users could develop apps that deal only with TCP/HTTP.
In order to facilitate this, the loopback interface is created on startup using ifconfig. This allows applications to talk to each other on 127.0.0.1 within the Cage. Any traffic that goes to or from the user process is over loopback via the data plane. The control and data plane have a series of VSOCK servers and clients that facilitate communication over the channel. The data plane will send traffic to the user process on the port that is specified in its Dockerfile during Cage build.
Thanks to this layer, when you develop an app and deploy to a Cage, it will run the same way it does when you develop locally on your own machine.
Enclaves are built without any networking out of the box. This is an intentional security feature that reduces the attack surface of the enclave. Even if your app fell victim to a supply chain attack by pulling in a malicious dependency, there would be no way the dependency could exfiltrate sensitive data from your enclave.
The only problem is that many applications will require access to the remote domains to be useful. We have customers using our products to make payments, sign blockchain transactions, and more, so it needs to be possible for them to execute requests out of the Cage in a secure manner.
When we started to design the egress networking system for Cages, we knew the following was important:
In order to create a seamless transition between running an app on a normal server and an enclave we have to take a look at what happens when you initiate a network connection in an app:
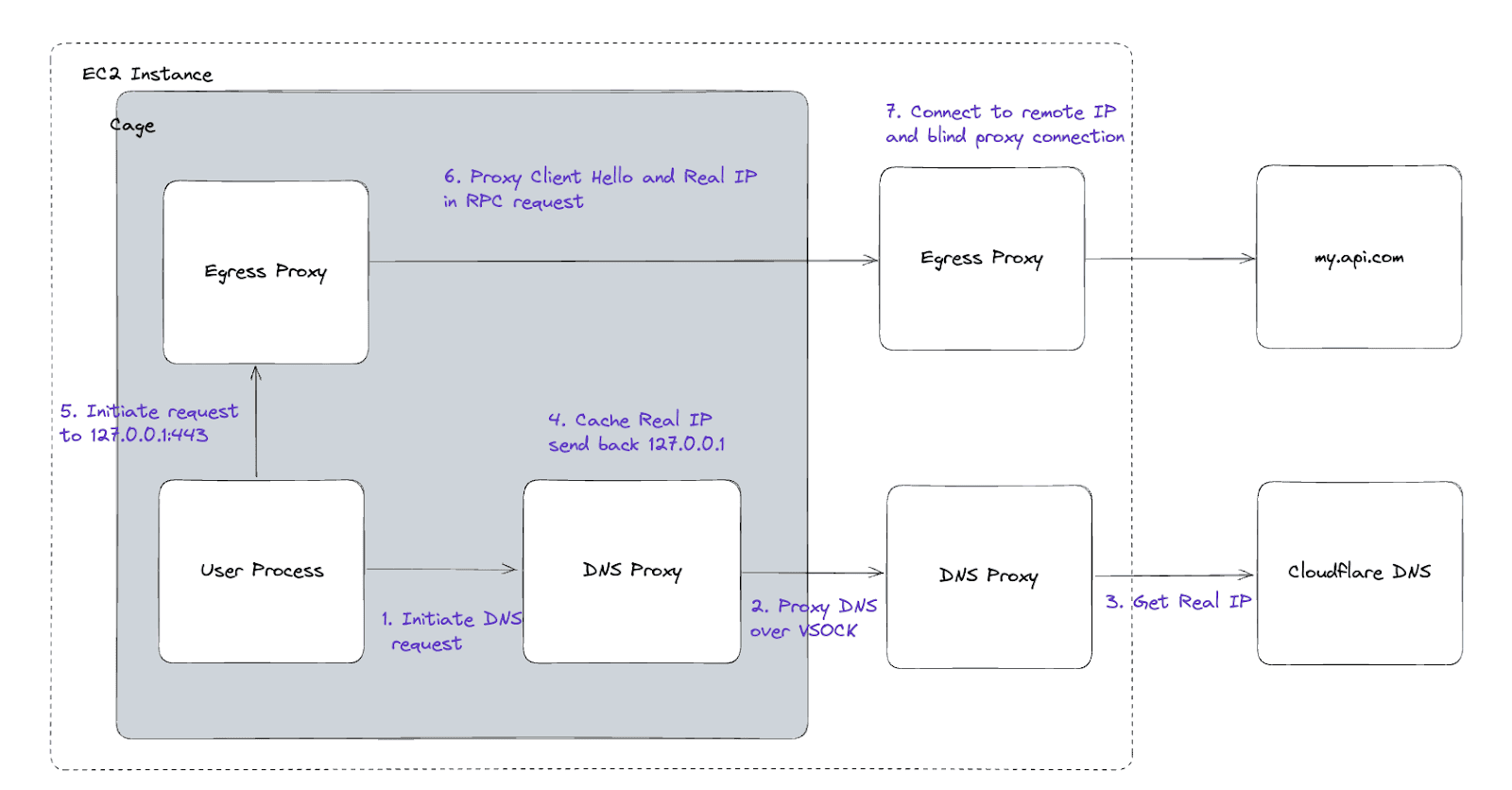
We replicated this behavior on the enclave to allow optional network egress. We created a DNS server on the enclave listening on 127.0.0.1:53. It accepts DNS traffic that comes from the user process and proxies it over VSOCK to the DNS proxy on the control plane.
The DNS proxy on the control plane will forward the request to a Cloudflare DNS server. Cloudflare returns the real IP, which is sent back to the control plane and then the DNS proxy on the enclave.
The on-enclave DNS proxy caches the real IP and sends a fake packet with 127.0.0.1 as the A record back to the user process. The user process thinks the remote IP is 127.0.0.1, so it will initiate a request to 127.0.0.1:443 (for HTTPS traffic).
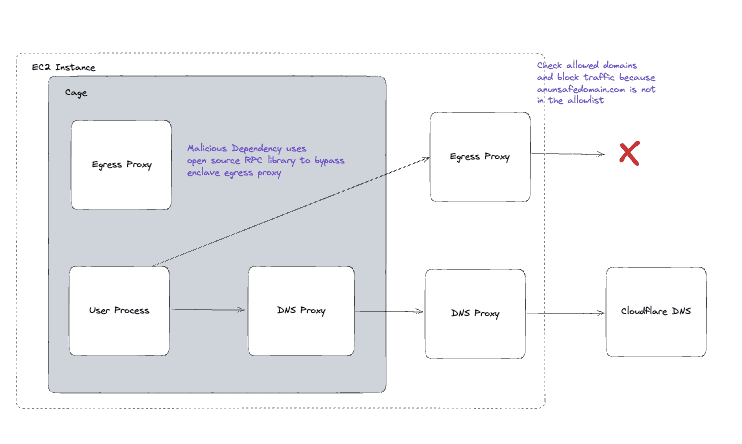
An egress proxy listening on loopback on port 443 will receive the request from the user process. The egress proxy will then parse the hostname from the TLS client hello and lookup the real IP from the cache. An RPC request will then be made with the real remote IP, port, and the Client Hello bytes sent from the user process.
The control plane will open up the connection to the remote host and send on the initial bytes of the TLS connection, the rest of the traffic will be encrypted, and the control plane will be unable to peek at the traffic flowing between the enclave and the remote host.
Some traffic won’t use port 443; for example a connection to a Postgres database will use 5432. To support this, egress ports can be specified in the cage.toml and an egress listener will be set up on that port to manage the requests. The only restriction on the traffic is that it must be over TLS, otherwise it wouldn’t be possible for the hostname to be obtained from the initial handshake. More importantly, it means traffic isn’t allowed to leave the enclave in an unencrypted state.
All of the code required for Cage egress is behind Rust feature flags in the codebase. This means that when the app is compiled without egress enabled, the PCRs of the app will be different to if the feature was enabled, and the source code will not exist on the enclave. The control plane that is deployed with the Cage also won’t have any egress or DNS proxies. This allows end users to be confident that egress out of the enclave is not possible on their Cage when it is disabled.
When you build a typical application, you’re generally pretty sure what domains it will access when it is running. You’re confident that because you wrote and reviewed the code, you know where data will be sent from the application. Unfortunately, thanks to typosquatting, it can be surprisingly easy to accidentally pull in a malicious dependency if you’re not careful. You can mitigate this risk by double-checking legitimate package names and using dependency scanning, but we wanted to make sure that we also protected against it in Cages for users who want network egress to be enabled.
When a user configures egress, there’s an option to add the expected domains for the service. Any request to an unexpected domain will be blocked at the start of the TLS handshake. This list will be enforced in both the data plane and the control plane by comparing the domain from the TLS handshake to a list of allowed domains initialised in the environment on startup.
The domains are restricted in the data plane on the enclave so users can attest that they are being enforced.
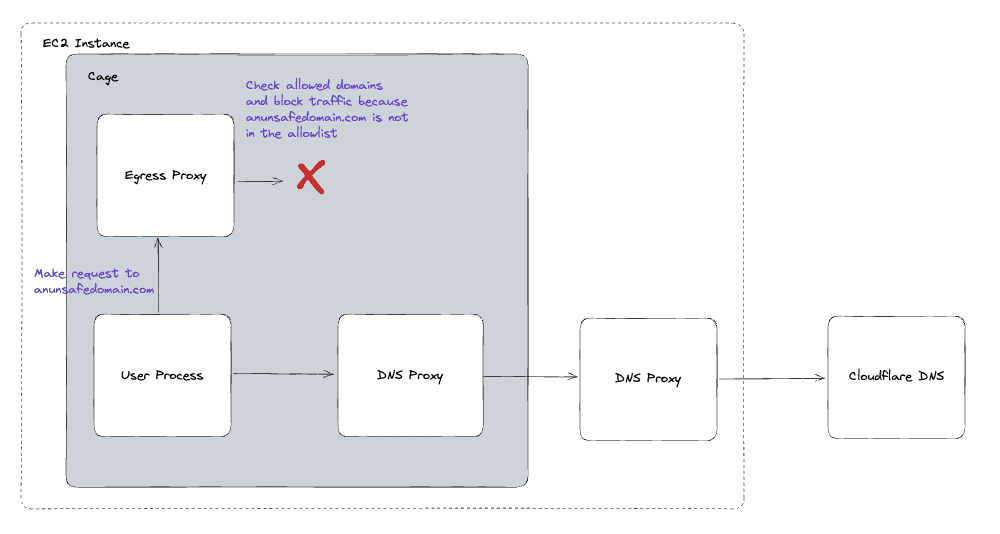
We enforce it in the control plane too, because there is the possibility of an extremely contrived supply chain attack that would target a Cage user and use RPC to make a request out of the enclave, bypassing the enclave egress proxy. By enforcing the same logic in the control plane we protect against this.
Dealing with VSOCK directly and the inability to make requests to the internet are two things that can slow down and discourage engineers from using enclaves. We have developed an enclave runtime that allows users to start up a simple app and let Evervault handle the rest. Of course, it’s all open source, so you know exactly what’s happening in the enclave. Try it out today and get 14 days free when you sign up for Cages now.

Secure your payment pages against script and security header attacks while complying with PCI DSS 4.0 requirements, 6.4.3, and 11.6.1.
Shane Curran
Multi-payment processor systems integrate multiple payment providers to handle transactions. Use Multi-psp to boost coverage to local populations and minimizes net transaction fees.
 Mathew Pregasen
Mathew Pregasen