When discussing data security, it’s easy to focus on protecting data while it's processing or in transit. However, it's just as important to consider the security of data at rest – data that's stored on a hard drive, in a database, or in a cloud provider storage bucket. Mistakes with data at rest can lead to serious data breaches, so taking steps to secure it is essential. One way to do so is with encryption.
What is data encryption?
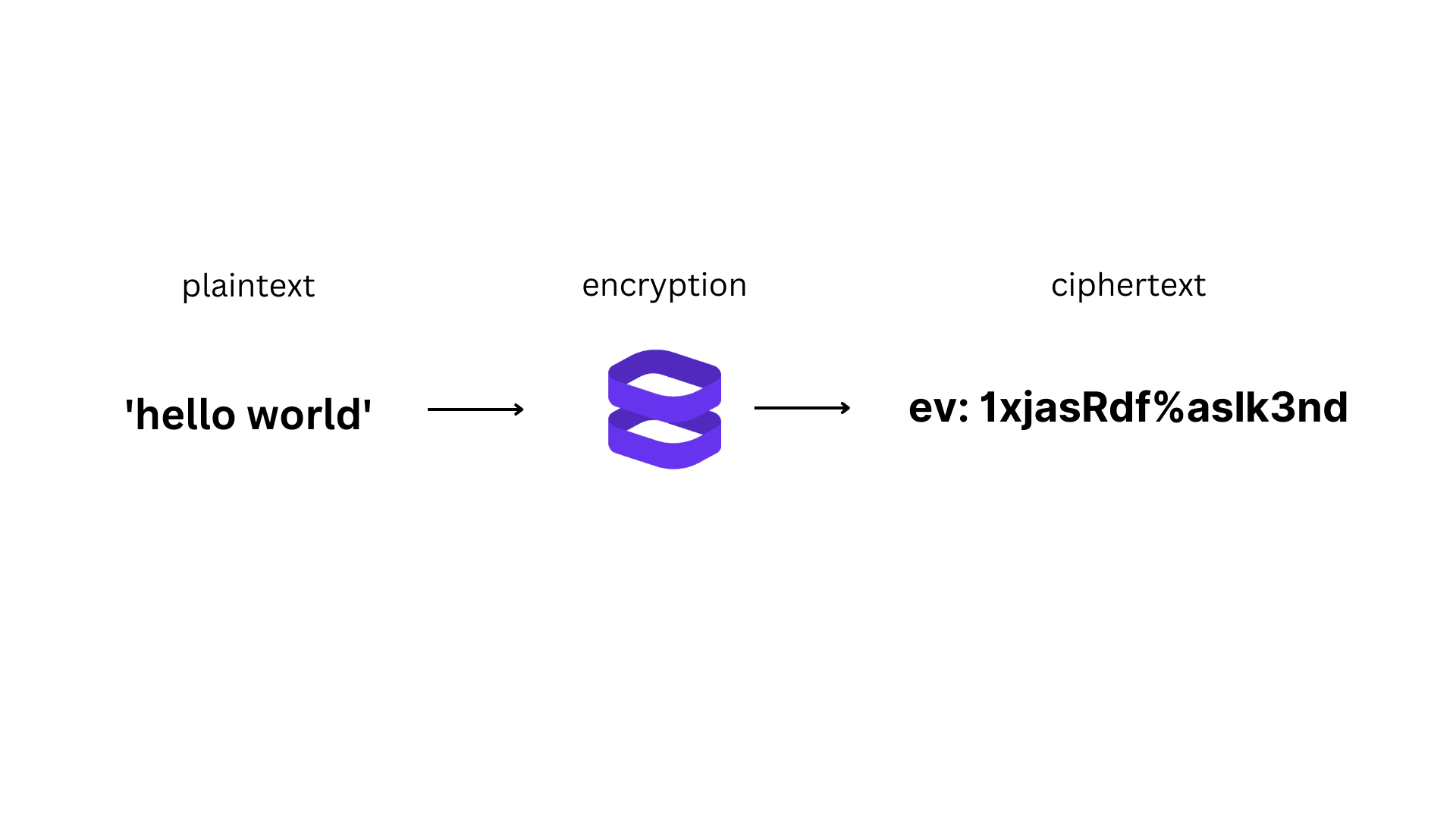
Encryption uses cryptographic algorithms to convert data from plaintext to ciphertext, and the data can only be decrypted or returned to its original state using the right key. Cryptographic keys work similarly to physical keys, where they will lock (encrypt) data, and only the correct key will unlock (decrypt) the data.
Types of encryption include symmetric encryption, where the same key is used for encryption and decryption, and asymmetric encryption, where a pair of keys (public and private) are used for encryption and decryption. Encrypting sensitive data ensures no one can access it, even if cyberattacks or data theft occur. As Aditya Patel said, “The efficacy of a good encryption scheme depends upon the strength of the encryption algorithm (the lock) and the encryption key (the key).”
Implementing encryption at rest can be a step in the right direction for your security strategy, but it won’t be effective if it’s not configured correctly. In this post, we’ll look at common mistakes that organizations and developers make with encryption at rest and learn best practices for keeping sensitive customer data safe.
What is data at rest?
There are three states of data:
- Data in transit or data in motion: Data in transit is data that is being transferred or transmitted between locations. This transfer could happen over a network like the internet, within a computer’s RAM, between local file storage to cloud storage, or vice-versa. Examples of data in transit include uploading a file to an S3 bucket, sending an email, or submitting a card payment to an e-commerce business.
- Data in-use or in process: Data in-use refers to any information being actively updated, processed, accessed, and read by a computer system or application. While in use, the data is stored in a non-persistent digital state in RAM, CPU caches, or CPU registers. Examples of data in use would be running a validation check, processing data in an algorithm, inputting data into a form, streaming media, or editing a doc or spreadsheet.
- Data at rest: Data at rest is any data that is not actively being used or processed and is not in motion but is in storage either on a user’s local device, hard disk, or in cloud storage. Examples of places data might be stored include S3 buckets, databases, log files, plist files, XML data stores or manifest files, or cookies.
Suppose Alice wants to sign a PDF saved on her computer and share it with Bob. The document on her computer is currently data at rest. Alice opens the PDF to sign it and attaches it to an email, which now makes the data in use. She then sends the email to Bob with the PDF attached, which makes the data in transit. Once Bob downloads the file to his local machine, the data will be at rest.
Mistakes with encryption at rest
Storing unnecessary data
You must follow any regulatory guidelines for the type of data you are storing and its geographic location. Regulatory requirements aside, storing unnecessary data that isn’t critical to your application or business can be a security risk because it creates additional attack surface for potential threats. The more data stored, the more opportunities for attackers to exploit vulnerabilities and gain access to sensitive information.
Let’s say, to safeguard against this, you decide to encrypt all the sensitive – but presumably unnecessary – data saved to your data store. Even though your data is technically safe, you’re going to rack up costs on storage and encryption, either from a vendor you’ve chosen or from your own implementation. You’re also going to risk latency and performance issues. If you don’t need to store it and won’t need it in the future, don’t store it.
2. Using weak encryption
Using weak encryption means choosing encryption algorithms or methods that can be easily circumvented via brute-force attacks. This could happen by:
- Using an algorithm or method that is vulnerable to collision attacks. Examples of these include SHA-1, Triple DES, MD5, and RC4.
- Implementing a strong encryption algorithm incorrectly. The Open Worldwide Application Security Project (OWASP), a nonprofit foundation that works to improve the security of software, recommends AES for symmetric encryption with a key of at least 128 bits (ideally 256 bits) and a secure mode, and elliptical curve cryptography (ECC) with a secure curve such as NIST Curve P-256 for asymmetric encryption. Even if you are using one of these algorithms, it can be easy to make implementation errors.
- Using your own cryptographic algorithms. It can be tempting to roll your own, but it’s a risky choice. There’s a reason why OWASP simply says, “Don’t do this”.
Test your code or choose a reliable testing provider (we use Cure53 as a pen tester) to identify any areas of weakness. You must also be aware of built-in encryption methods chosen by your database or cloud provider.
3. Misalignment on the architectural choice of where encryption happens
When you’re developing software, designs can change quickly, requirements get miscommunicated, or misunderstandings happen while maintaining legacy code. But it’s important to plan where encryption will happen on your machine or in your stack. Mistakes or inconsistencies could lead to data leakage or worse.
There are four common approaches to encrypting data at rest:
- Full-Disk Encryption (FDE): This protects the data at a hardware level on a computer, mobile device, or other storage device by encrypting all of the data on the device, including the operating system, applications, and user files. FDE provides a high level of security for data at rest, as it makes it very difficult for an unauthorized person to access the encrypted data on a stolen or lost device. However, it does not protect against attacks that may occur while the device is in use, like malware or keyloggers.
- Transparent Data Encryption (TDE): This executes encryption and decryption within the database engine and applies them to the entire database. This protects data at rest but does not protect data in transit or data in use. Microsoft, IBM, and Oracle use TDE. Unfortunately, in many cases, database encryption schemes are self-defeating as data and keys end up in the same database (thus, privileged users with access to the database can access encrypted data).
- Application-Layer Encryption (ALE): This is encryption done within your application using an encryption API like Evervault or a cryptographic algorithm of your choice. If you use ALE correctly, you do not need to depend on underlying transport or at-rest encryption methods — however, if you only encrypt on the server side, data passing between the client and server is vulnerable.
- Field-Level Encryption (FLE): Sometimes referred to as Client-Side Field Level Encryption (CSFLE), this allows you to encrypt individual fields on the client-side before it is sent to the server and keeps the data encrypted in every state. It will never be seen in plaintext by the hosted database or any user that has direct access to the database. CSFLE is available from some providers and can be set up with Evervault using Inbound Relay.
If you plan to rely on encryption software or default solutions (for example, built-in server-side encryption with Amazon S3), find out what the provider offers, such as the strength of encryption, key management, and how it will integrate with your overall encryption scheme.
4. Poor key management
Key management is a challenging problem — even world-class engineers easily make mistakes with cryptographic keys. So if you make any of the following errors, know that you are not alone – but put practices in place to remediate them now.
- Storing the keys in the same place as the data: Keep the keys isolated from the data, so that should an attacker gain access to one, they still will not have access to the other. Ideally, you should store the keys and data on separate systems and in an encrypted format.
- Being unaware of where the keys are used: Even if the keys are safely stored, you may unknowingly leak keys into swap files, crash dumps, logs, and other areas that might be seen by attackers.
- Putting the keys in publicly shared source code: Don’t hard-code the keys, don’t check them into version control systems, and try not to store them in environment variables. If you must keep them in a configuration file, put strict permissions on it.
- Failing to rotate and back up keys: Encryption keys must be changed or rotated if the previous key has been compromised; if the authorization time (cryptoperiod) has elapsed; if it’s hit the limit of the amount of data it's permitted to encrypt; or if there is a new attack against the algorithm used has been announced. It’s a good practice to rotate your keys and implement a secure backup capability – Encrypted data with lost keys can never be recovered.
- Using weak or predictable keys: You should always use a cryptographically secure function to generate keys randomly. Please, no pet names or birth years!
Amazon has a helpful framework for approaching key management in the form of three questions:
- Where are the keys stored?
- Where are the keys used?
- Who can use the keys?
You can use these answers to guide any fixes you need to make. Using a key vault or key management service will take care of many of the issues above — Evervault will handle key storage, rotation, and provisioning on your behalf.
5. Not encrypting sensitive data in other states
Implementing CSFLE and utilizing secure enclaves to process sensitive data can ensure it stays protected throughout your system. The number one problem with only implementing encryption at rest is that it doesn’t protect data in use or in transit. Though your data will be secure at rest, as soon as it’s retrieved to run logic on it or send it from your server to the client, it will be accessible in plaintext form and can be compromised.
Using encryption at rest to help secure data
Encryption at rest should be one piece of a broader security strategy. See the OWASP cryptographic storage cheat sheet for more best practices and follow their guidelines. And if you have time, watch these talks:
It can be overwhelming to consider all these factors when looking at your system. One option is to use Evervault to encrypt your data and manage your keys.
Evervault is the first encryption platform to let you encrypt, process, and share sensitive information without touching it in plaintext. This is built on the Evervault Encryption Engine (E3) running on Nitro Enclaves. Using enclaves means that Evervault can never access your data.
For encryption at rest, our data structure is designed so that you don’t need to change your database configuration or models. You can store Evervault-encrypted data in your database as you would plaintext data. Check out our docs for more details on the Evervault Encryption Scheme and our approach to key management.
Encrypt, Process, and Share Data Securely at Scale
Register for a Free Evervault account to see how it works, with unlimited encrypts and up to 2,500 decrypts.




 Shane Curran
Shane Curran