
Introducing Evervault Page Protection: Securing payment pages from JavaScript attacks
Secure your payment pages against script and security header attacks while complying with PCI DSS 4.0 requirements, 6.4.3, and 11.6.1.
By Shane Curran
Shane Curran
Shane Curran

Engineer
Evervault is on a mission to encrypt the web, and to achieve that we’re building encryption infrastructure for developers. Relay is our latest product designed to make integrating field-level encryption into your app as easy as possible.
Relay operates as both an ingress and egress gateway. Relay is a globally distributed encryption proxy. As an ingress gateway, Relay sits in front of your app, automatically encrypting sensitive data in your requests at the field-level and decrypting the responses so your users’ experience is unchanged by our encryption.
As an egress gateway, Relay intercepts your server’s communication with the broader internet to decrypt sensitive data before it’s forwarded to trusted third parties.
You can integrate Relay in 5 minutes by including our SDK and changing a DNS record.
In our previous post, “How we built E3”, we explained how we built the Evervault Encryption Engine — our encryption service, which we deploy globally in AWS Nitro Enclaves. All of our products internally are designed to run alongside E3 and use it for any sensitive encrypt and decrypt operations.
One of the most important points raised within that post is why we believe the web needs an Encryption engine in the first place:
As developers, we’re used to abstraction and simplicity across our workflow: Stripe abstracts away payment networks, Twilio abstracts away telecoms, and AWS and Vercel neatly abstract away servers for us; all this functionality is integrated through a few lines of code.
The same is not true for encryption — the most important security tool developers have to protect their users and datasets.
To date, integrating encryption has been left up to the individual developer on a project-by-project basis. There are some useful open source libraries to abstract away the implementation details, like Ring in Rust, cryptography in Python, and bouncycastle in Java. But none of them can abstract away the operational overhead of rolling your own cryptography (that’s not their purpose). As an engineer, you’re still tasked with key storage, rotation, and ensuring sound implementation. Relay aims to fix this. By making industry-standard encryption trivial to integrate and abstracting away the operational complexity involved in managing keys. Relay lets you begin encrypting your data at the field level in as little as 5 minutes without changing how you build your apps.
Another issue with server-side encryption is that the data is still reaching your server in plaintext before you get the opportunity to encrypt it. A vulnerable dependency can grant unwanted access to your plaintext data (think log4j), and if you’re handling credit card information, your backend is now within scope for PCI compliance. By routing traffic through Relay, your sensitive data is encrypted before it ever touches your app — using keys managed by Evervault.
TLS and encryption-at-rest are a start, but it’s not enough. The handling of your sensitive data should follow the principle of least privilege. Your entire app does not need to see your customer’s SSN or credit card number in plaintext. Treating data as the ultimate security endpoint allows you to effectively scope access to the individual functions or services that need it. If your server doesn’t process the data and simply sends it to 3rd party APIs, then there’s no reason for the data to exist in plaintext on your infrastructure at all. Relay can decrypt data as it’s sent to trusted 3rd party APIs, and block data from being sent to unexpected domains.
Core takeaway: Implementing and managing encryption is difficult to get right and a major time sink for most engineering teams. Relay is an abstraction layer over Evervault E3, designed to make it simple to begin encrypting your most sensitive data before it reaches your server.
Once we knew what we wanted to build at a high level, we began working backwards from the user experience we wanted to offer. We wanted to make it simple to integrate Relay; it should be as easy as changing a DNS record. We didn’t want to impact how you build your apps, beyond improving your security posture with field-level encryption. We wanted to improve your visibility into your app's traffic patterns. It had to be low-latency and reliable.
Compiling all of this down to a definition gave us:
Relay is a highly reliable, globally distributed, low-latency encryption proxy. Relay shouldn’t hold any key material, and should use E3 to perform any sensitive cryptographic operations. Relay should use its position in the stack to help you better understand your app’s traffic.
Breaking the core functionality into design requirements gave us the following:
Let’s explore these further:
Relay has to be globally distributed with multi-region failover
The ultimate aim for Relay is to be as broadly distributed as the best-in-class CDN providers like Akamai, Fastly, and Cloudflare. To accomplish this we need to get Relay as close as possible to your end users. We want to run multiple instances of Relay on every continent, and are actively working towards getting there.
Additionally, we want Relay to be as reliable as possible, so we support multi-region* failover to insulate you and your customers from any vendor outage we may experience.
We appreciate how sensitive Relay’s position is in your stack.
*Note: If you have data residency concerns, we support single jurisdiction processing.
Relay should not hinder the builder.
We want Relay to be so performant that you almost forget it’s there. Relay should meet the original value proposition of Cloudflare, make your app faster, and more secure.
Relay shouldn’t prevent your backend from talking to legitimate 3rd party APIs, and it shouldn’t hurt your customers’ use of your API. To accomplish this, Relay needs to act as a layer around your app to update all inbound & outbound traffic.
Relay should use E3 for any decryption operations.
We need Relay to scale up to meet the cumulative traffic of all of our customers. This isn’t currently possible with Relay in a Trusted Execution Environment (TEE) for several reasons (resource constraints, and a lack of observability being the most obvious). Because of this, Relay must rely on E3, which does run in a TEE, to perform any decryption operations. This means that Relay requires a low latency channel to an E3 instance at all times.
Integration must be simple.
Developer Experience (DX) is one of our key focuses at Evervault. We know that our products have to be easy to use and think about if we want to change how developers think about handling sensitive data. Relay needs to support simple integrations like creating a DNS record, or simply updating a hostname in a config file. Relay doesn’t need to know about what cloud provider you’re hosted on, or what backend framework you use. It should just work.
Relay should generate useful insights based on the traffic it sees.
Relay’s position is as powerful as it is sensitive. Without tracking any sensitive information from your network traffic, we can significantly improve the modern DX of running an API: discovering your hottest API routes (along with their status codes and latency changes over time), preventing sensitive data from being sent to a rogue third party, and proactively suggesting sensitive fields to encrypt.
Core takeaway: Relay acts as a low latency, highly available ingress and egress gateway. It is deployed with the Evervault Encryption Engine (E3), so it can decrypt data. Relay leverages the traffic it sees to improve the DX of building APIs.
Having established what we needed to build, we began investigating different approaches. It was clear that we had two paths to explore:
This felt like our best bet. We didn’t want to reinvent the wheel, and we knew that proxy servers like Nginx, and Envoy could be fine-tuned to handle heavy load with predictable performance. We began investigating their support for scripting. We had a few requirements here to build Relay: we needed to be able to mutate any part of the request, and we needed to be able to communicate with E3 over vsock (you can read more about vsock in our E3 blog post). But most importantly, we needed to do all of this without disturbing the proxy’s event loop or creating performance bottlenecks.
While this seemed like the most promising approach at first, we were unable to find a way to modify the request body and call E3 without blocking the event loop. In Nginx, we were able to intercept the request, and communicate with an E3 instance over vsock using Lua FFI to call into a purpose-built Rust module. But in doing so, we completely blocked up the Nginx event loop, and the proxy’s throughput rendered it completely unusable. Our experiment with Envoy was short lived as it did not expose the request body to the Envoy WebAssembly API at the time.
Having hit a dead end with implementing Relay as a plugin to existing proxies, we began to spike out rolling our own proxy for Relay. As a first step, we needed to land on a language to use. We went with Rust. Performance of Relay is a major concern, so we needed a language which would let us move quickly, and safely. Rust had just exceeded C in several performance benchmarks, offered compile-time detection of concurrency problems, and had crates offering vsock support.
We can define the two main flows in Relay as follows:
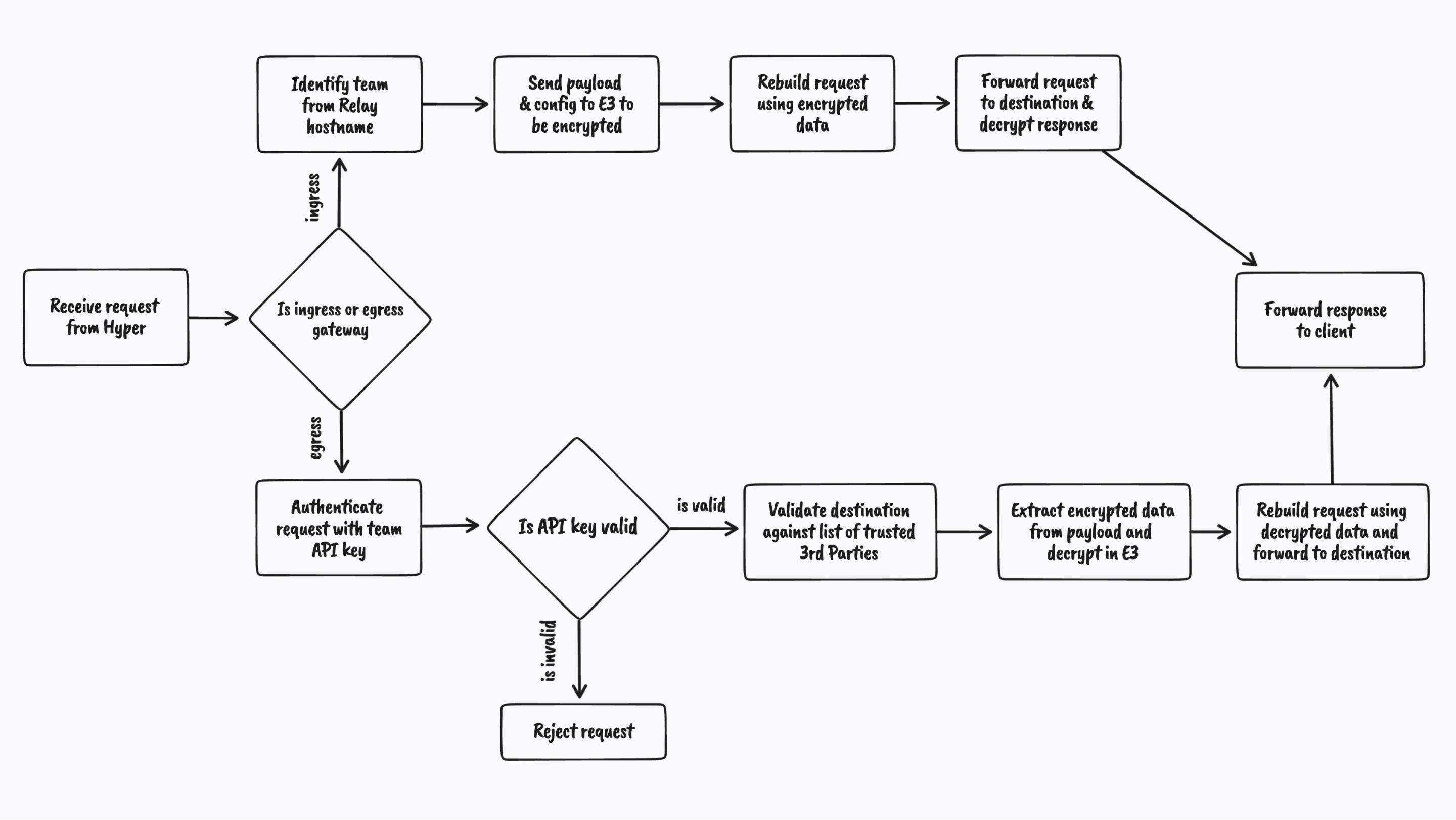
As an ingress gateway, Relay has to:
Receive requests & identify team from Relay domain
Each Relay has a unique hostname, so to retrieve the corresponding configuration Relay checks the hostname against a map of known hostnames to configurations.
Retrieve the Relay’s configuration
Each Relay’s configuration contains settings which specify which fields in your request are encrypted, and where the data is sent. Currently, encryption configuration is a list of JSONPath selectors for which fields to encrypt, and the elliptic curve to use for encryption. In future, we plan to extend these controls to support validating inputs before encrypting them.
Concurrently rebuild the request with encrypted data and establish a connection to the Relay’s destination
To reduce latency, we concurrently encrypt the data in the request via E3 while we perform a TLS handshake with the destination.
We encrypt the data by sending it to E3 over vsock with the relevant configuration options. Once we receive the encrypted data in the response from E3, we need to replace the plaintext values in the original request before we forward it to your server. This is generally pretty straightforward — Relay only supports structured data (currently JSON, url-encoded forms and XML) and uses user-defined paths to identify fields to encrypt.
Forward the modified request to the destination
Generally, the destination will be your API, but you also can use Relay to mask/redact data in payloads before it reaches a third-party. All destinations must support TLS for Relay to connect to them.
Forward the response back to the client
After the destination has handled the request and responded, Relay will forward the response to the client. If the response contains Evervault encrypted data, we will decrypt it before forwarding. This means you can store encrypted sensitive customer data in your database and display it in your frontend, without worrying about having to decrypt it.
As an egress gateway, Relay has to:
Act as an HTTP CONNECT proxy performing TLS Termination
When using Relay in egress mode, clients must first trust the Evervault CA (this is handled automatically in our JavaScript and Python SDKs). The clients then treat Relay as a standard HTTP proxy, initiating the connection with a CONNECT request. Relay responds to the CONNECT request by performing a TLS handshake with the client using a self-signed certificate.
Clients which support CONNECT-over-TLS are authenticated using a Proxy-Authorization header containing their team’s API key on the initial CONNECT request. For clients without TLS-over-TLS support, the connection is established unauthenticated (to prevent secrets being sent in plaintext), but every subsequent request is expected to include the Proxy-Authorization header.
Authenticate the request using the team’s API Key
Relay uses the API Key included in the requests to it as an egress gateway to identify the team that it needs to decrypt data for. This is done using a request to E3, so that Relay does not need to store any credentials.
Validate the destination against list of trusted 3rd parties
You can specify a list of destinations that you trust to send traffic to via Relay. If you have specified an allowlist, Relay will block the request before it reaches the destination, responding with a status code of 403 and an x-evervault-error-code header with a value of forbidden-destination. If you haven’t specified an allowlist, Relay will allow all authenticated traffic & skip this step.
Extract encrypted data from the payload and decrypt in E3
Unlike Relay in ingress mode, any Content-Type is supported for outbound traffic to third parties. Relay scans your request for text which looks like an Evervault encrypted string. These strings are then sent as part of a payload to E3 where they are decrypted. Relay then uses the decrypted strings in the E3 response to replace the ciphertexts in the original request before sending to 3rd parties.
Forward response back to the client
Once Relay has received a response from the 3rd party, it is forwarded back to the client. In this situation Relay is largely a blind passthrough, and does not modify the response at all.
Core Takeaway: Relay operates in two distinct modes, ingress and egress. Ingress mode provides field-level encryption to prevent sensitive data from existing in plaintext on your servers, while egress mode supports decryption of sensitive data before it’s sent to trusted third parties. Using both modes in concert allows you to treat encrypted data as though it were plaintext.
Rust has an incredibly active community, who have built some fantastic crates. Relay makes extensive use of some of Rust’s largest projects: Tokio & Hyper.
If you have used Rust before, then Tokio & Hyper need no introduction. Tokio is an asynchronous runtime for Rust—with first-class support for tracing—which powers much of Rust’s async-ecosystem, including Hyper; a performant and compliant HTTP implementation.
Hyper leverages the core Service abstraction of another popular Rust crate, Tower, to make it simple to build modular and reusable network applications. A Service is an asynchronous function which converts a Request into a Response or an Error (i.e. async fn(Request) -> Result<Response,Error>). Referring back to our description of the two main Relay flows, it’s clear that the Service abstraction allows us to neatly package Relay’s logic — identify the team and authenticate the request, call into E3, rebuild the request, and forward the request, returning the response or an error.
Core takeaway: Relay is built in Rust using Tokio for its async runtime, and Hyper as its HTTP server library.
Relay's CI/CD and infrastructure are much less intricate than E3's. We use GitHub for source control at Evervault, so we have heavily adopted GitHub Actions for our CI/CD. Relay has a straightforward pipeline. It’s compiled on Ubuntu, runs its tests and then deploys to staging or production from the develop and main branches respectively. We’re looking into ways that we can automate latency tests against PRs to prevent any latency metrics from regressing, taking inspiration from Safari’s Page Load Test.
Originally, Relay was deployed on EC2 using ECS in each of our supported regions. Each of these instances ran an instance of E3 for Relay to connect to. We then ran two Relay daemons, one in ingress and one in egress mode, on each of the instances so that we could guarantee our Relay tasks were evenly distributed across the fleet.
We recently migrated to run Relay on ECS Fargate to decouple the deployment of Relay processes from E3, and to improve our ability to scale the number of Relay instances. We now deploy Relay to multiple instances on Fargate, half running Relay in ingress mode and half running in egress mode.
E3 is still deployed on EC2 using ECS (This is a hard dependency of Nitro Enclaves). While we previously had Relay communicate with E3 over VSock, we have updated Relay and E3 to communicate over mutual TLS within our VPC. To do this, we run a server on the same EC2 instance as E3 which terminates the TLS connection and pipes the serialised RPC message directly onto a VSock connection.
We scale our EC2 instances using an EC2 autoscaling group on the instance memory and CPU usage. Each new instance will start up an E3 daemon which will begin receiving all of the required configuration data. Once E3 has loaded in its data and has marked itself ready, the Relay instances will begin sending traffic to it. (You can read more about E3’s lifecycle in our previous blog post.)
Alongside Relay & E3, we deploy a health-checker task which we refer to as ‘Pulse’. Pulse gives us greater flexibility and control over our health checks. We run health checks from Pulse every 5 seconds, and maintain a buffer of results within Relay. When Relay receives a health check from our load balancer, it scans the buffer of the past ~2 minutes of Pulse results for a failure. If a failure has occurred in the past ~2 minutes, the load balancer health check will fail, and the Relay instance will be weighted out before being replaced.
We use AWS Global Accelerator to route incoming traffic to the closest healthy Relay instance using the AWS backbone. This has two key benefits - it reduces the latency between the client and Relay, and allows us to support multi-region failover. AWS Global Accelerator gives us two static IPs, which we use as the values for an A record for *.relay.evervault.com. Unless you need to restrict your traffic to a single jurisdiction, Relay will always ensure your customers are on the fastest path.
Core takeaway: Relay is deployed to EC2 on ECS in daemon mode and autoscales based on its CPU and memory consumption. We deploy a health check service alongside Relay to accurately identify unhealthy Relays. We use Global Accelerator to route users to the closest available Relay instance as quickly as possible.
The config data to be stored by Relay is received as JSON, and is read-heavy. Relay has no requirements for any complex queries; it only needs to retrieve configuration data for a Relay by hostname. To keep latency as low as possible, we opted for an in-memory cache stored as a Hashmap. Because of the concurrent nature of a web-server, we needed a hashmap designed for concurrency, such as Dashmap. Dashmap gave us an intuitive hashmap API with low latency reads.
To support custom Relay domains and Mutual TLS (mTLS) targets, we needed a way to store the certificates. We began to investigate using EFS as a shared file system across our fleet of ECS tasks. While EFS would have worked as a low latency, scalable storage engine for certificates, we quickly realised that EFS does not support cross-region replication without the use of AWS DataSync. While DataSync would have been able to replicate our data cross-region, we needed a lower latency solution.
We decided to use AWS S3 for certificate storage which had several benefits: lower cost, greater storage capacity, and first-class support for an event-driven architecture. This meant we could provision certificates on a single Relay instance, upload it to S3, and have a notification published to an SNS topic to alert the remaining Relay instances to download the latest certificate.
Core takeaway: Relay uses Dashmap to store its config in memory, and uses AWS S3 to persist TLS and mTLS certificates.
Similar to E3, Relay needs to maintain an in-memory cache of the most recent Relay configurations as defined by our customers. This requires a closed-loop control plane to receive and provision configuration updates across every Relay instance in each region.
Every time a customer creates or updates a Relay within the Evervault dashboard, our API writes the latest data to our PostgreSQL database and then publishes a notification on an SNS topic. This SNS topic is used to trigger a Lambda function in each region. These SNS notifications are then formatted as an HTTP request to be sent to each of the Relay services to update the in-memory cache.
Core takeaway: Configuration updates for Relay are published to an SNS topic which triggers a Lambda to push the latest data to the individual Relay services.
To make sure that Relay provided valuable insights to your app’s traffic, we built in traffic logging from Day One. When a request is received by Relay, it begins a new Transaction Context which is associated with your team. As Relay processes your request and response, it decorates the context. By the time the response leaves Relay, the context will contain: the number of encrypts & decrypts involved, the roundtrip latency, the non-sensitive headers in the request and response, the status code and much more.
It’s worth stressing that we do not record any potentially sensitive information from the request. When tracking request and response headers, Relay checks each header against a set of known non-sensitive headers. If the header exists in the set, it’s recorded, otherwise, it’s recorded as ***. Relay also records the body of JSON requests and responses, but it replaces any value found in the body with a generic string corresponding to the type of the value (e.g. string, number, boolean). We also record if the value was encrypted when it passed through Relay by prefixing the type with encrypted_.
When Relay is finished with the full request/response lifecycle, the request transaction is logged and sent to CloudWatch. We have a filtered CloudWatch subscription which only detects the transaction context logs. The subscription invokes a Lambda, which parses the transaction and inserts it into the current daily index in our ElasticSearch cluster.
Since the initial release of Relay, we’ve extended its support to include:
And we have even more exciting features on the way:
Hopefully, this post has given you a clear understanding of why, and how we’re building Relay. The core takeaways are:
Implementing and managing encryption is difficult to get right and a major time sink for most engineering teams. Relay is an abstraction layer over the Evervault Encryption Engine (E3), designed to make it simple to begin encrypting your most sensitive data before it reaches your server.
Relay acts as a low-latency, highly available ingress and egress gateway. It is deployed with E3 so it can decrypt data. Relay leverages the traffic it sees to improve the DX of building APIs.
As an ingress gateway, Relay provides field-level encryption to prevent sensitive data from existing in plaintext on your servers, while, in egress mode, it supports decryption of sensitive data before it’s sent to trusted third parties. Using both modes in concert allows you to treat encrypted data as though it were plaintext.
Relay is built in Rust using Tokio for its async runtime, and Hyper as its HTTP Server library.
Relay is deployed to ECS Fargate and it autoscales based on its CPU and memory consumption. It communicates with the Evervault Encryption Engine over mutual TLS, which is piped into an established VSock connection to the Nitro Enclave. We deploy a health check service alongside Relay to accurately identify unhealthy Relays. We use Global Accelerator to route users to the closest available Relay instance as quickly as possible.
Relay uses Dashmap to store its config in memory, and uses AWS S3 to persist TLS and mTLS certificates.
Configuration updates for Relay are published to an SNS topic which triggers a lambda to push the latest data to the individual Relay services.

Secure your payment pages against script and security header attacks while complying with PCI DSS 4.0 requirements, 6.4.3, and 11.6.1.
Shane Curran
Multi-payment processor systems integrate multiple payment providers to handle transactions. Use Multi-psp to boost coverage to local populations and minimizes net transaction fees.
 Mathew Pregasen
Mathew Pregasen