
Introducing Evervault Page Protection: Securing payment pages from JavaScript attacks
Secure your payment pages against script and security header attacks while complying with PCI DSS 4.0 requirements, 6.4.3, and 11.6.1.
By Shane Curran
Shane Curran
Shane Curran

Engineer
In Why we built Cages, we explained our motivation for building a product to make it easy for developers to deploy Trusted Execution Environments (Secure Enclaves). In the first part of this post, we'll explain how Enclave builds work without Evervault, and in the second, we’ll walk through how Cage builds work with Enclaves. We’ll share our approach, the challenges we faced, and the open-source tools we used to enable reproducibility.
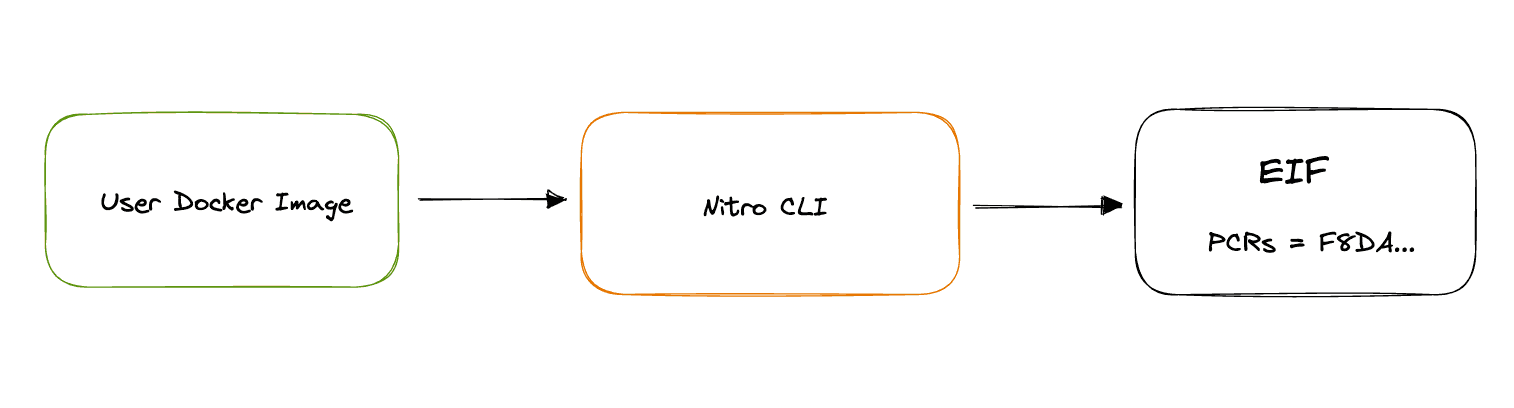
Any arbitrary Docker container can be run in an Enclave. The container just needs to be converted to an Enclave Image File (EIF). This can be done using a one-liner command to the Nitro CLI provided by AWS:
1nitro-cli build-enclave --docker-uri my-docker-image --output-file my-docker-image.eifThe .eif file is created, and some measurements of the EIF are displayed. These cryptographic measurements are called Platform Configuration Registers (PCRs). They are hashes of various parts of the file system and, if included, the certificate used to sign the EIF. When you attest the container which is running in your Enclave, you're basically checking that the PCRs of the running container are the same as what you built on your machine. Hence, the integrity of PCR values is crucial.
When we set out to build Cages, one of the key features we had in mind was to bootstrap the Enclave with all the extra logic needed to run a web server. To do this, we split the Cages runtime into two parts: the control-plane which runs on the host EC2 instance, and the data plane which runs inside the Enclave.
This meant we needed to find a way to inject our data-plane into the Enclave. Further, we needed to determine how to handle this injection while ensuring that users do not need to trust Evervault.
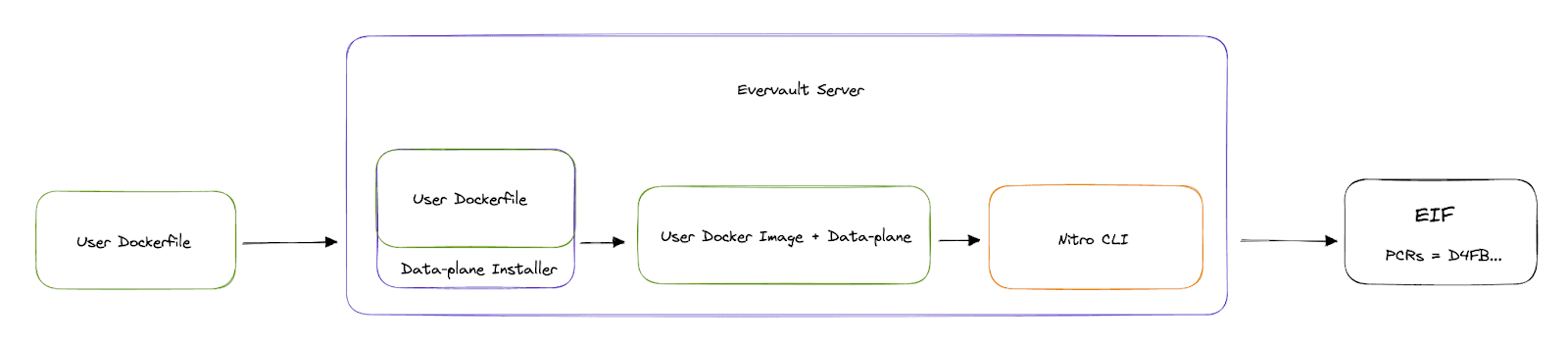
It would’ve been much easier to build the Enclaves on our servers rather than on our users' machines. We already had a server-side build pipeline for our Functions product which we could’ve adapted for Cages. Plus, we wouldn't have to build and maintain a CLI for our users.
It would work something like this: the user uploads their full source code and Dockerfile to our servers, we inject the data-plane installer, build the Enclave, and show the user the PCRs of their Cage.
Seems fine, right? Not really. This actually breaks the integrity of the PCRs. There would be nothing stopping Evervault from doing this:
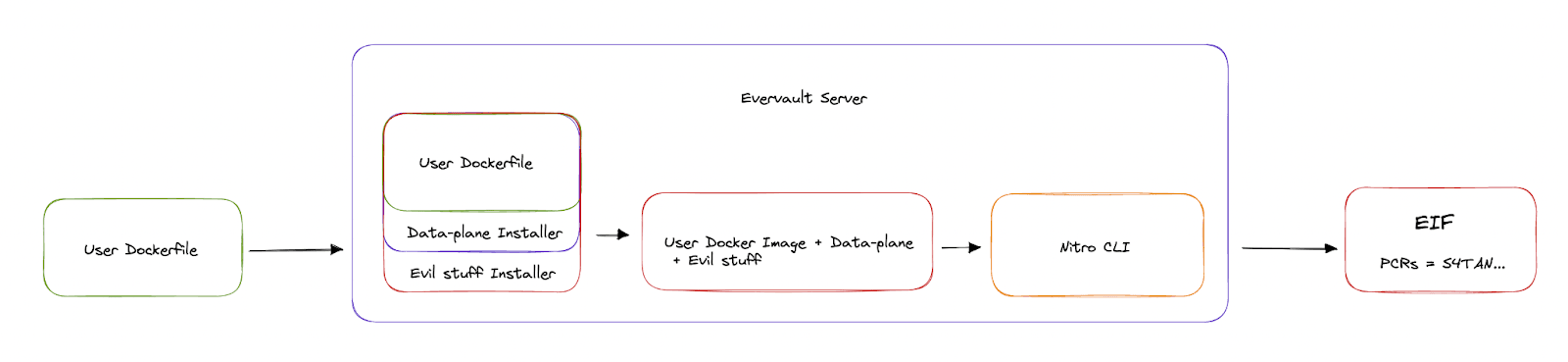
So sure, you may be able to attest that the PCRs of the container running in your Enclave match f001ed, but you would have to take our word for what those PCRs correspond to. Your attestation would be wholly dependent on our build system's integrity. To us, this is not a sufficient guarantee.
To avoid this, we decided to design the system so users would build their Cages locally using a CLI that we built. The ev-cage build command takes in an arbitrary Dockerfile, injects the data-plane, and uses the Nitro CLI to build it into an Enclave Image File.
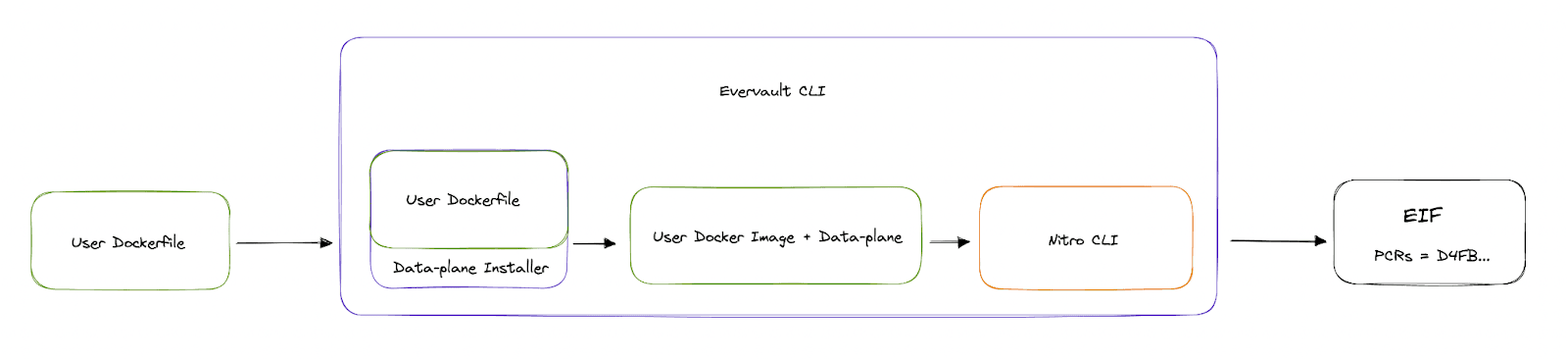
Evervault is removed from the trust model via transparency:
In this section, we'll share some challenges we faced building the Cages CLI, in hopes of helping others who run into similar problems.
** Warning: this involves some CLI inception. We're about to say CLI 15 times **
We wanted to use the nitro-cli build command in our Cages CLI, so we needed to depend on the Nitro CLI. But the Nitro CLI has some dependencies that only compile on Linux, and we obviously don't want to restrict Cages to Linux users only.
We decided to run the Nitro CLI via a Docker container. Our CLI makes a call to the Docker CLI to run an amazon-linux-2 image with the Nitro CLI installed, running the sacred nitro-cli build-enclave command as its entry point.
Then we realized that the Nitro CLI also makes calls to the Docker CLI. So we would somehow need to give the Nitro CLI access to the Docker CLI. Maybe Escher would've enjoyed this loop, but we didn't!
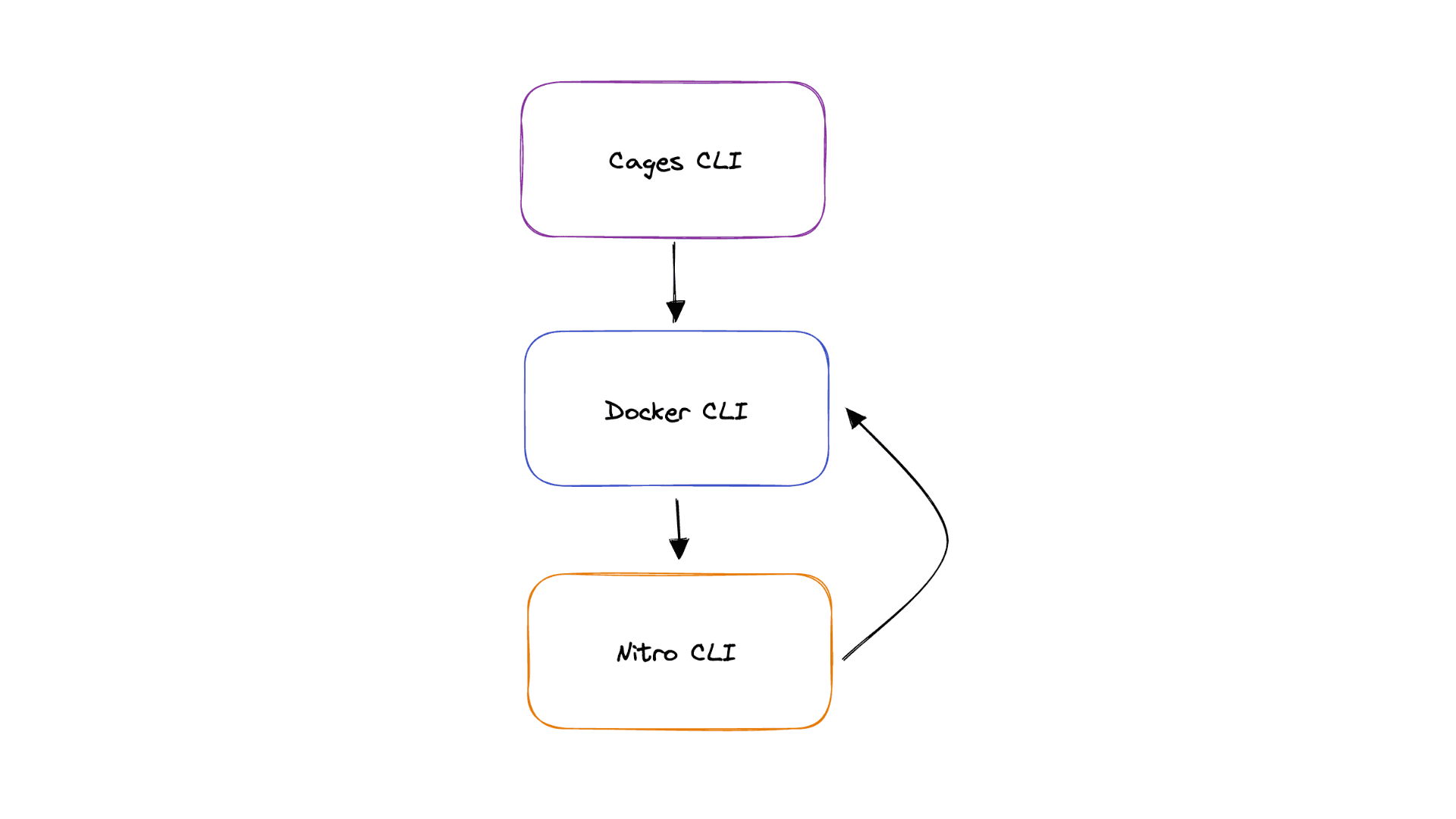
The solution: We give the amazon-linux-2 container access to the host machine's Docker CLI by using this arg in the docker run command:
1docker run … -v /var/run/docker.sock:/var/run/docker.sockIs there any risk to our users in giving us access to their Docker CLI? Nope: as both the Cages CLI and Nitro CLI are open-source, the user can see that we're only using it to build and run the relevant containers.
A core focus of Cages is to abstract away the complexity of running a service in an Enclave. To achieve this, we needed to be able to forward all traffic to your service over TCP instead of leaving you to interact with VSock directly.
To do this, we bundle your service with some of our own processes: Beyond the data plane itself, we include a process supervisor (we use runit in the Cage), and some tools to create the in-enclave loopback interface (ifconfig).
Typically, these tools would be installed using the available package manager. However, that wouldn’t work in our case. We wanted Cages to be as flexible as possible, and trying to account for every potential distro-specific package manager in our Cage builds seemed futile. Additionally, most package managers create cache files on installation which include the timestamp of the package installation. This wouldn’t normally be cause for concern, but any timestamp in the Cage’s file system will change the resulting PCRs. Ideally, two subsequent builds of a Cage, regardless of the environment, will produce the same PCRs.
To get around this, we created a small runtime installer which is included in the Cage Dockerfile using an ADD directive. The installer bundles up static builds of both ifconfig and runit with a small install script that checks the current environment to see if either tool is already available, and, if not, installs them.
Serving our own installer has further benefits:
A further challenge of building Cages from existing Docker images is supporting reproducible builds. Given the importance of attestation in confidential computing, it is reasonable that the same inputs for a Cage (dependencies and source code) should produce the same outputs (PCRs). This lets you know, in advance of a release, what values you should be attesting.
But getting reproducibility in container builds is a hard problem. The reproducible builds working group has made major strides in fighting the entropy of container builds, but the problem persists. A few of the problems include:
So how can we rely on PCRs for attestation? What does it mean to attest a container that produces a different measure on every build, even without changes?
The value of attestation is reduced massively when the PCRs aren’t consistent. Attesting a specific build of a container is not as compelling as attesting the container across builds in a predictable way. You should be able to build an image locally to know what the PCRs will be ahead of a release. That way, your production service can be updated to attest the new PCRs ahead of time.
Fortunately, there are tools that enable this. Kaniko can enable builds of OCI-compliant images in a reproducible way. It does this by spoofing the system time, causing any timestamp generated during the build to be recorded as the UNIX epoch. This has some drawbacks — it removes any helpful context from when your last changes were made.
Recently, BuildKit added support for reproducibility. BuildKit uses the same approach as Kaniko with some nice updates. For one, you can set the source epoch to be used for reproducibility. This opens up some nice options, like setting the epoch to the time of the last git commit. This lets you retain some context of when the last change was made to a container and will be consistent across your team members’ machines and your CI.
Reproducibility is coming soon: We’re working towards reproducibility in simple images, and detailed guides on reproducibility for more complex images.
It was important to us to build Cages in a way that made it easy for developers to deploy to an enclave, with PCR integrity in mind as well as not having to trust Evervault. See how it works and sign up for the beta here.
In the next post in our ‘How we built Cages’ series, we’ll dig into deploying – unpacking the complex process of deploying and managing an Enclave in a production environment.

Secure your payment pages against script and security header attacks while complying with PCI DSS 4.0 requirements, 6.4.3, and 11.6.1.
Shane Curran
Multi-payment processor systems integrate multiple payment providers to handle transactions. Use Multi-psp to boost coverage to local populations and minimizes net transaction fees.
 Mathew Pregasen
Mathew Pregasen