- June 20, 2023
Federated learning works like magic. Unfortunately, people don't really trust magic.


Mathew Pregasen
Content Contributor
Do you have a friend that really, really, really cares about their data not being harvested? Federated learning is that privacy purist’s pipe dream. At least, in theory.
Federated learning is a machine learning strategy where training is delegated to local devices using local data. A central server corresponds with local devices to aggregate the gradients into a global model without accessing the raw data. Federated learning is a PET, a privacy-enhancing technology, as it hypothetically safeguards user data while still harnessing its training potential.
Federated learning was born out of growing training needs in a privacy-conscious world. Often, federated learning is used for machine learning models built on inherently sensitive data, from medical exam recommendations to keyboard predictions (including Gboard, Google’s keyboard). After all, “Everything you have ever typed is sent to Google’s servers” isn’t a very comforting headline, even to the “I don’t care if they steal my data!” tech bro.
While federated learning is privacy tech, it isn’t perfect. Federated learning opens some fresh security challenges due to the underlying data’s inaccessibility. It’s a two-sided problem; (i) model contributors could attack the model, negatively impacting efficacy, and (ii) the model’s maintainers and users could reverse engineer a contributor’s raw data.
Perhaps it’s best to revisit that opening line—federated learning might not be a privacy purist’s pipe dream. It might actually be their nightmare, especially when organizations promise a hands-off approach to data training but have flaws in their implementation.
Federated learning 101
Federated learning is a privacy-based improvement upon centralized learning. In centralized learning, local devices stream data to a central server, which in turn collects, organizes, and aggregates them for machine learning.
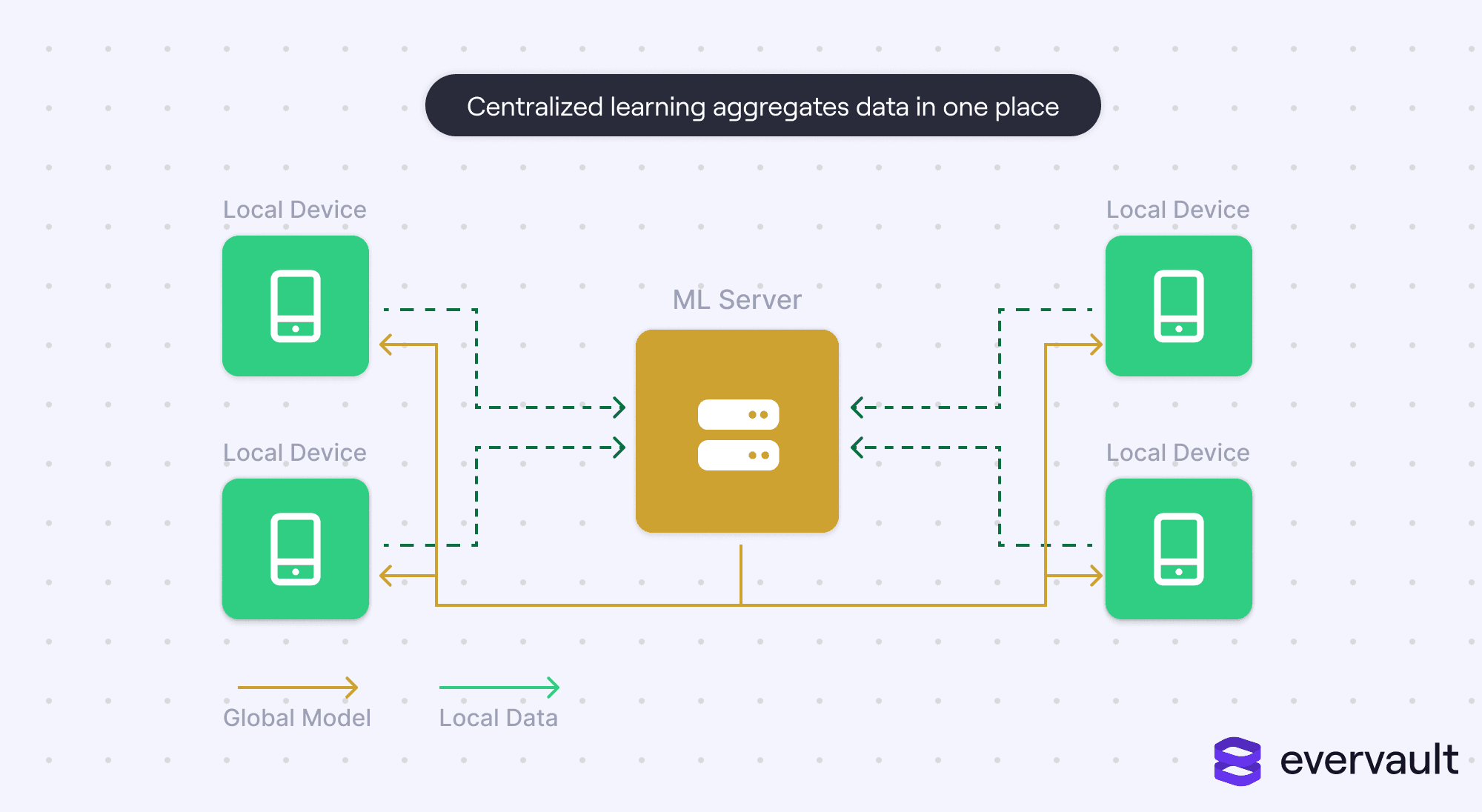
Centralized learning is the public’s stereotype of how machine learning works. And even when federated learning is used, the general public might struggle to distinguish it from centralized learning.
Because federated learning merges locally trained models—which are built on top of a shared global model—it barricades the server from local user data. Federated learning is particularly opportune for data that couldn’t possibly be collected due to extreme privacy circumstances (e.g., keyboard data) or laws (HIPAA’s restriction of medical data).
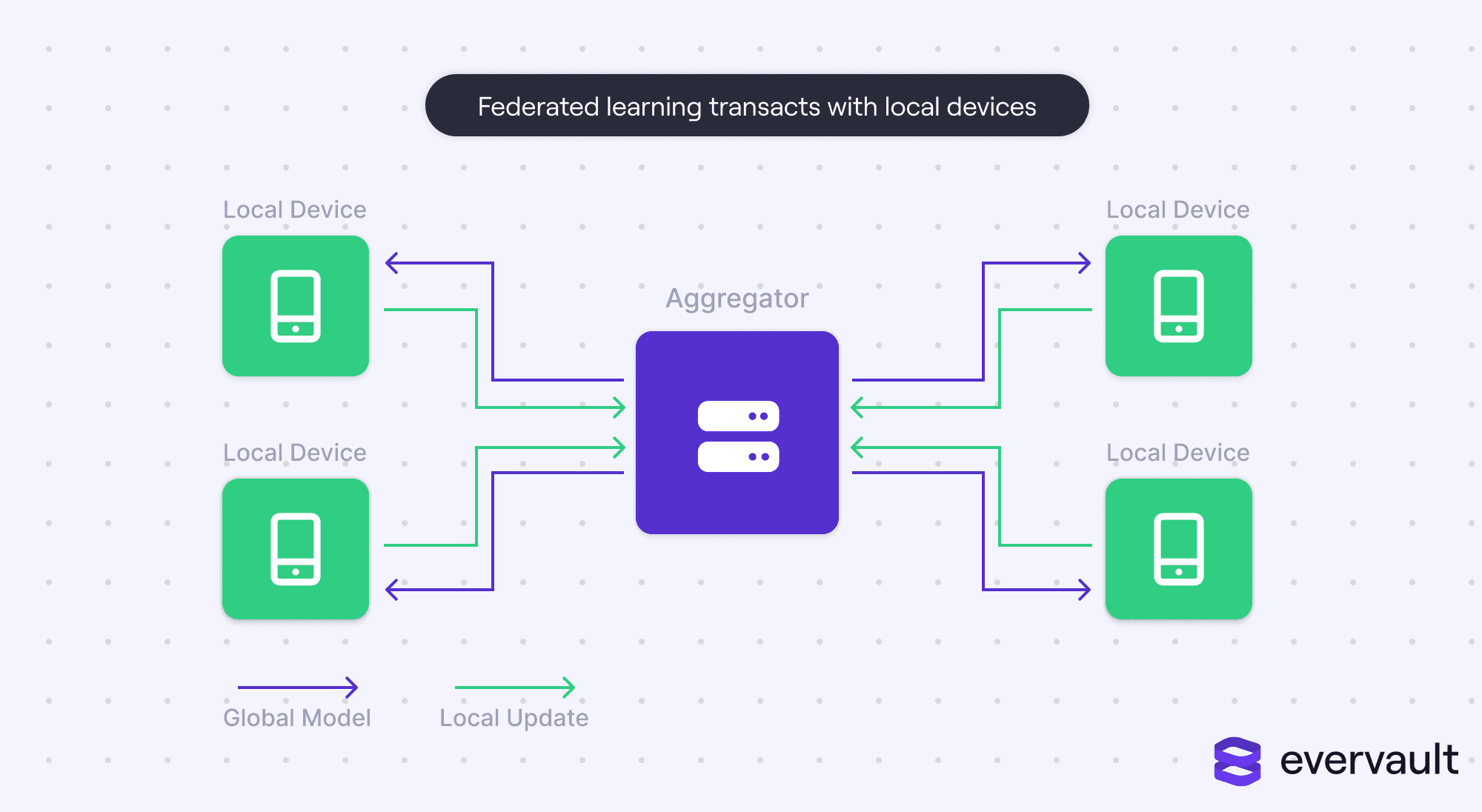
However, this two-stage training strategy dilutes the data, instead operating off of shared weights. The bigger issue is that the lack of transparency about the input data means that the data cannot be cleaned, de-biased, or preprocessed in any other way.
These factors underscore the general give and take between centralized learning and federated learning. In a nutshell, federated learning provides far better privacy, but centralized learning can produce more accurate models with less data while giving engineers better visibility into the underlying data.
The three parties
The curious thing about federated learning is that both the local device owners (the consumers) and the aggregator (the business doing the ML) can be breached. So, let’s first discuss the three stakeholders relevant to federated learning.
The aggregator
The aggregator is the service doing the machine learning. An aggregator could be “breached” if an external attacker exploits their federated learning program, contributing bad data (known as poisoned data) that ruins the model’s efficacy.
The sampled users
The sampled users are the owners of the training data. In the context of federated learning, a “breach” occurs if their data can be leaked or reverse-engineered by an external attacker (via snooping) or even by the aggregator. In general, users trust that the models submitted via federated learning can’t serve as a paper trail to their data.
The external attacker
Like any system, a potential party is an external attacker. In particular, federated networks need to safeguard their networks as there is a lot of data exchanged between the aggregator and the users.
So far, so good
Before diving into the various security breaches, it’s important to note that there have been no (reported) security breaches for federated learning systems. Of course, federated learning is still in infancy—both in terms of research and adoption—and history implies that any security system, no matter how secure, isn’t airtight.
Data Reconstruction
Data reconstruction is when local data is reverse-engineered from the submitted local gradients and has been at the forefront of federated learning research. Data reconstruction is a threat for obvious reasons; if a server could deduce the original data, then this defeats the purpose of federated learning. Or, worse, if an external attacker gains access to incoming packets, they too would be able to uncover user data.
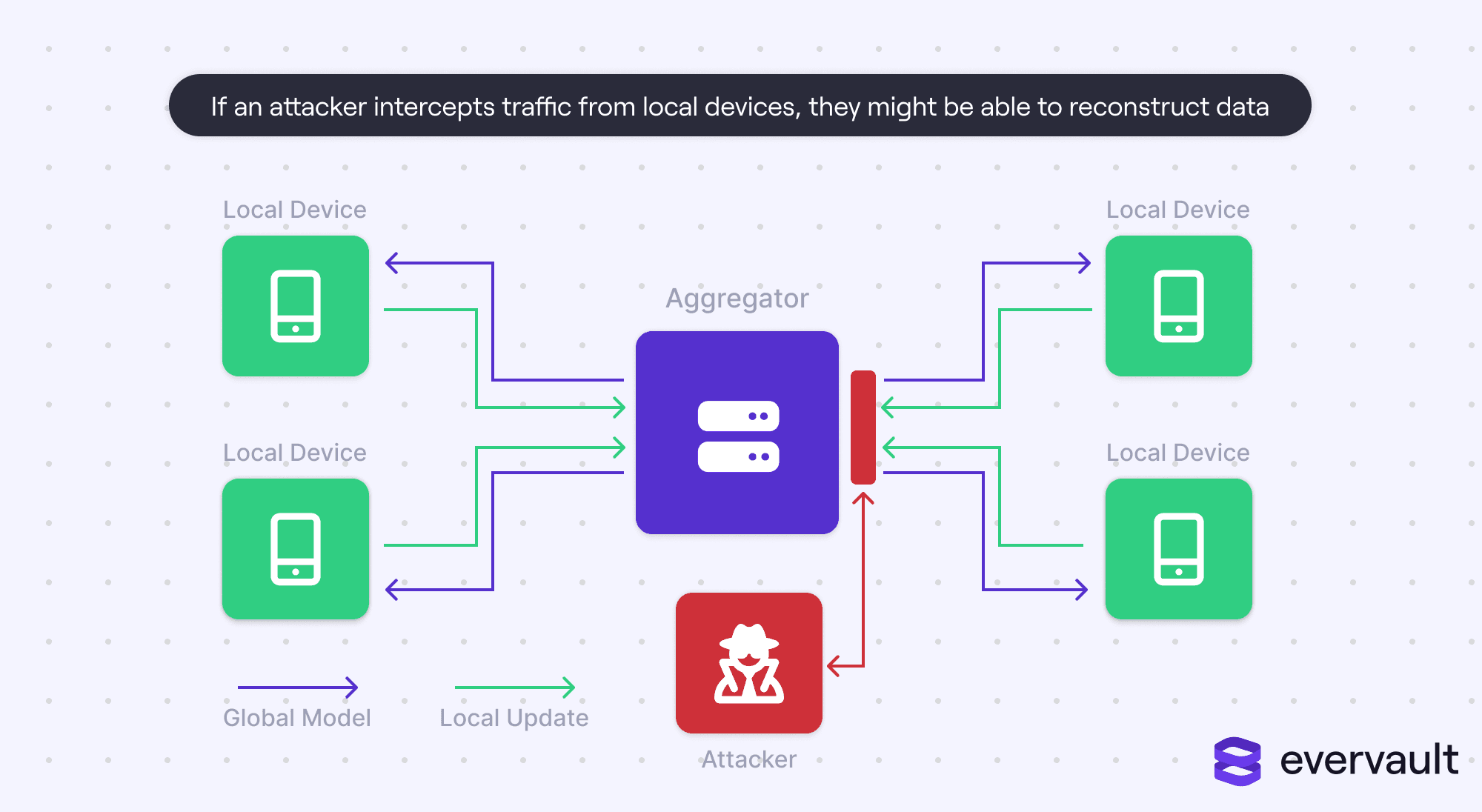
Data reconstruction has been difficult to pull off, but it is possible under some controlled scenarios. Accordingly, it’s critical that federated learning systems avoid these circumstances.
Small batch sizes hurt
It’s only possible to reconstruct client data if the original trained data, loss function, and training algorithm are known. The aggregator typically knows these things, but not necessarily the public (and by extension, external attackers). Of course, systems could be breached, typically through phished employee credentials, to gain access to these.
If models are trained on small batch sizes, the risk of data reconstruction is much higher via a model inversion attack, where an attacker takes advantage of the gradients dispatched to the server. An oversimplified explanation of this is guessing someone’s identity from just a few pixels of their face—much easier to do if you're choosing out of a class yearbook, rather than from a city database.
In general, federated learning should not be used unless the batch size is massive. The only exception would be for mission-critical tasks (such as cancer diagnosis) from a necessarily small sample database (e.g., exams for an ultra-rare type of cancer).
When small batch sizes are used, they can be protected if client devices apply multiple stochastic gradient updates locally (which are often used to conserve network usage by massive federated learning systems). According to a HAL paper, the success rate of reconstruction dropped from 100% to 13% when local steps increased from 1 to 19. Another research team discovered similar results.
The power of secure aggregation
Secure aggregation is a massive security upgrade to federated learning and has fooled all existing data reconstruction exploits. However, it also requires significantly more network bandwidth and coordination between client devices.
Secure aggregation involves client devices directly communicating with each other to share secret keys, and then using those keys to encrypt traffic proxied through the central server. The client devices will securely communicate to sum their values, allowing the server to absorb the model updates into the global model without knowing which client devices contributed which values.
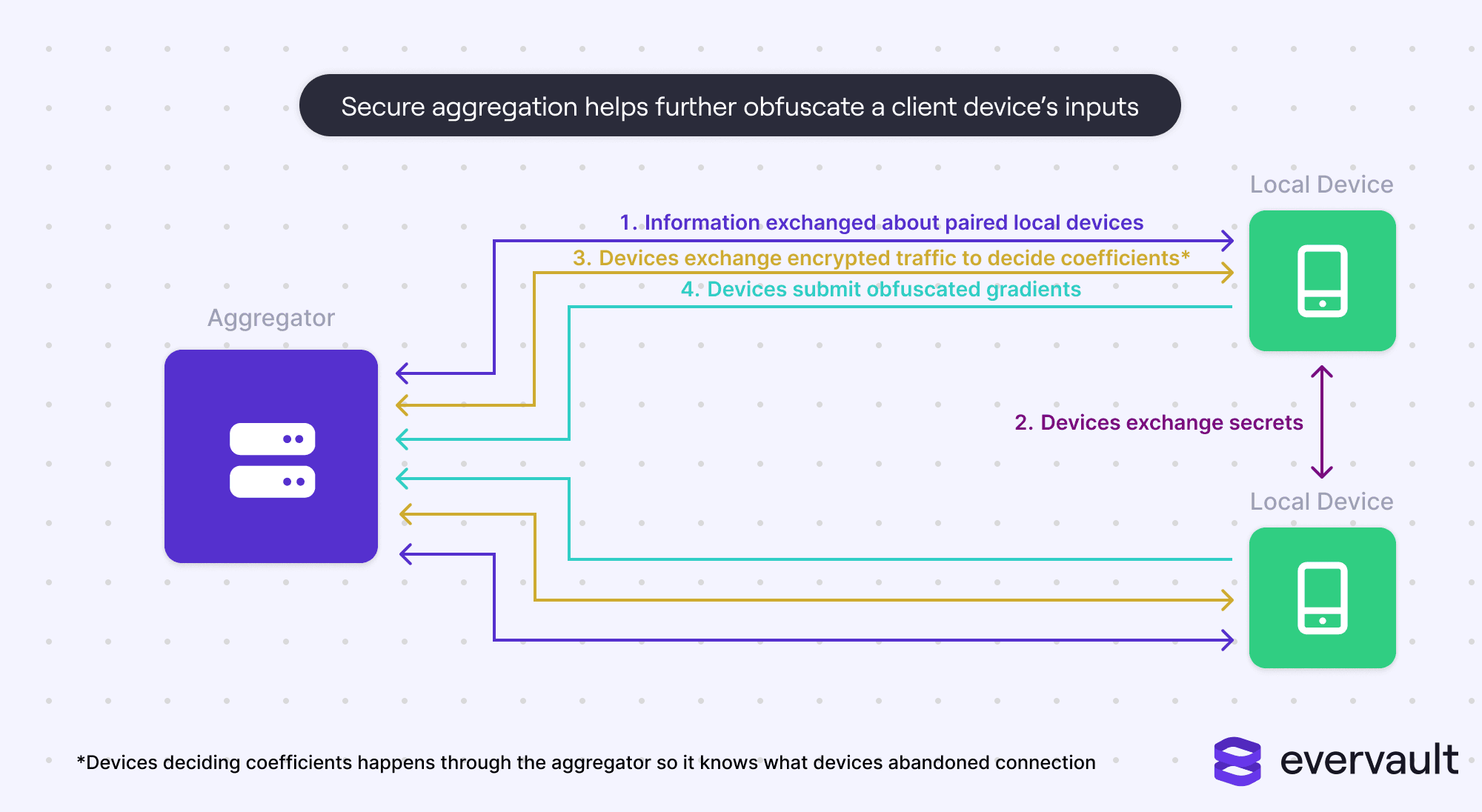
Secure aggregation can even happen with two devices. Multiple devices are more robust, though, as they can better stochastically handle unreliable devices that drop off midway.

The central server needs to proxy traffic between client devices because client devices are unreliable and may drop off; accordingly, the server needs to know to robustly compute values (via secure aggregation).
Data poisoning
Data poisoning is a type of breach that lives on the opposite end of data reconstruction. An attacker, posing as a user, could dispatch a fake model that messes up a training model.
A poor man’s version of data poisoning would be amassing a nontrivial percentage of client devices and dispatching random data in a training model. However, pulling off such a breach is difficult unless the polled client devices were from a small set—but typically, federated learning is used with massive, randomized sample sizes.
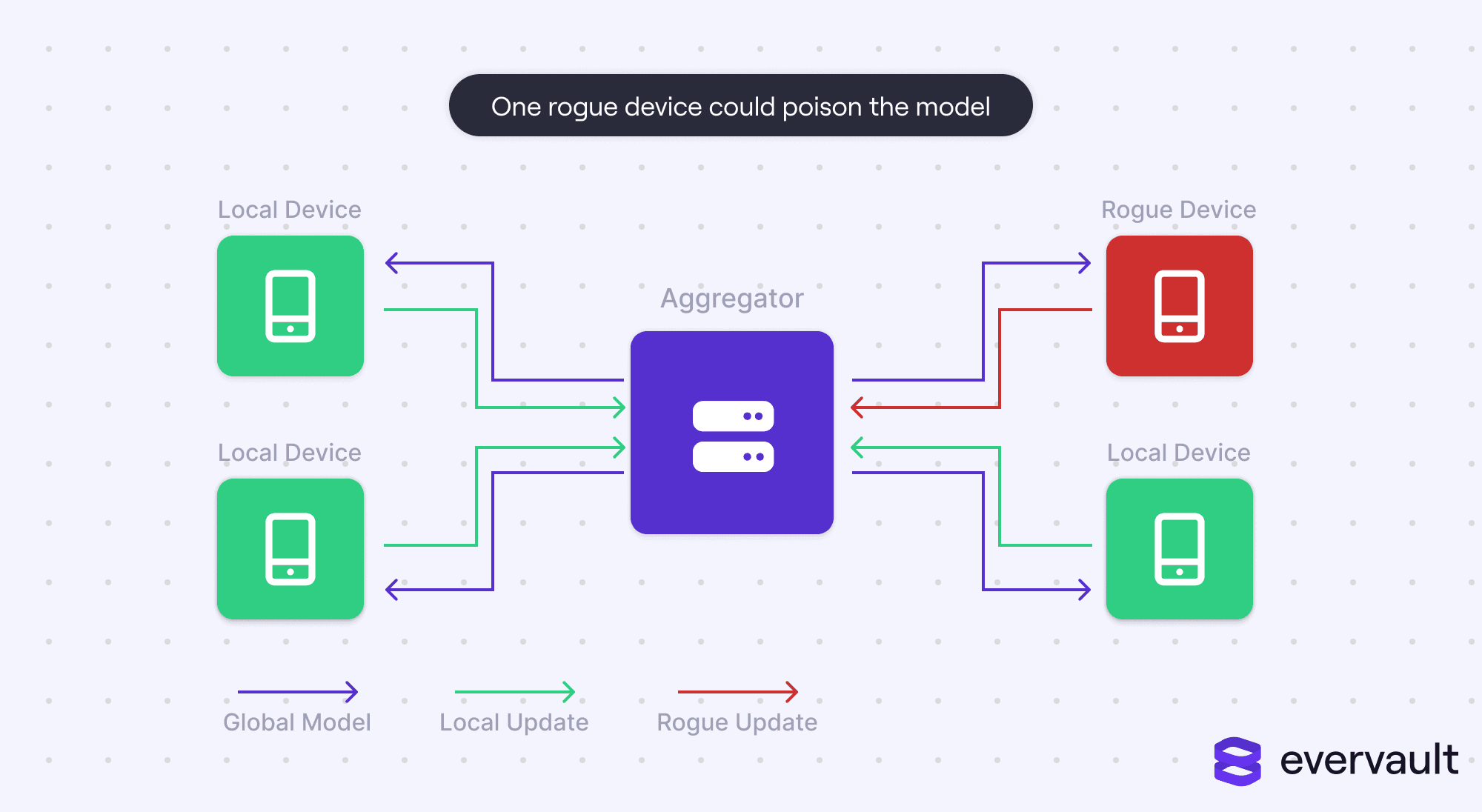
What’s more lethal is if a single device could wreak havoc in a training model by reverse-engineering a fake model that has the biggest impact on the global model. In fact, it’s been proven that a device could target specific classification labels and leave the others untouched.
There are two defense mechanisms against data poisoning. The first is monitoring how a single device impacts a model, and algorithmically identifying attackers to remove them. However, this isn’t possible if secure aggregation is leveraged to protect local devices against data reconstruction attacks because it obfuscates each individual device’s contribution. The second strategy is to add noise to all of the inputs.
Why this all (really) matters
With the explosive growth of OpenAI, self-driving cars, and AI-driven modeling, federated learning is only going to grow more popular. It will also impact how companies communicate with privacy-conscious consumers—because federated learning hypothetically safeguards user data, companies will inevitably market that as a promise.
But this only raises the stakes. It’s one thing for a company to leak user data during a breach. It’s another thing for the company to leak data while simultaneously promising that it wasn’t storing it. Because the average consumer isn’t equipped to grasp the difference between centralized and federated learning, they will just presume the company was dishonest.
This isn’t to shift the blame to the consumer or argue against federated learning. Federated learning is a good thing if companies are going to collectively perform machine learning. Rather, the onus is on businesses to ensure that they use federated learning with principled security, as even a single breach can be incredibly damaging. I can already imagine the headline: “Hooli promises it doesn’t save your data, but the history goes to show this doesn’t mean anything.” The stakes only compound when federated learning is used for day-to-day things like keyboard usage.
Closing thoughts
Federated learning is a major privacy improvement upon centralized learning without a massive penalty for producing accurate models. With its adoption by large companies like Google, it has proven to be a production-ready strategy at scale.
However, federated learning is hardly an airtight system. While there haven’t been any major security breaches to date, academic research indicates that an attack is very possible if the proper safeguards aren’t taken. Companies cannot assume that no attackers will access their systems and data—as employee phishing scandals have grown more common—and it’s critical, by extension, that attackers couldn’t reconstruct client data if they tried.
And given those products that increasingly depend on these models—which could be inaccurate or prejudiced—it’s important that developers take necessary safeguards to prevent data poisoning.
