
Introducing Evervault Page Protection: Securing payment pages from JavaScript attacks
Secure your payment pages against script and security header attacks while complying with PCI DSS 4.0 requirements, 6.4.3, and 11.6.1.
By Shane Curran
Shane Curran
Shane Curran

Engineer
AWS Nitro Enclaves have no networking by default, making it impossible to send requests from the Enclave to the internet. This lack of networking is perfect for some use cases, such as our Encryption Engine, but it dramatically reduces the number of applications you can run inside an Enclave.
In the early days of developing Evervault Enclaves, we knew that we would have to optionally enable egress traffic to allow users to build an extensive range of apps, for example, to facilitate card payments or blockchain transactions.
Throughout the Enclaves beta period, it became clear that our original design wasn’t universal enough to allow us to fulfil our goal of taking any app in a Dockerfile and deploying it to an Enclave without any code modifications required by the user.
For the Enclaves beta, we had one goal for egress networking, allowing an application to send requests to HTTPS endpoints (i.e. over port 443). We didn’t want the user to need to make any code changes, for example, adding a client proxy configuration that would only be used when the app was inside an Enclave. In hindsight, this narrow goal probably stopped us from getting to the current solution sooner.
The only channel between Nitro Enclaves and the outside world is over VSOCK. Language support for VSOCK is minimal, and many developers aren’t aware of it. It has a similar interface to TCP, but who wants to use a TCP-like client when there are tons of high-level HTTP libraries that will make development ten times faster? We wanted to abstract away the need for users to interact with VSOCK directly.
In initial research we explored the idea of using LD_PRELOAD to write our own shared libraries that would override underlying system calls to manipulate their behaviour. It became clear that this would be a nightmare to implement, not to mention the fact it wouldn’t work for statically compiled languages, so we quickly ruled it out.
If altering the system calls wasn’t a viable option, the next obvious place was to look at a slightly higher level to see if we could alter the behaviour of the system calls without touching the system code.
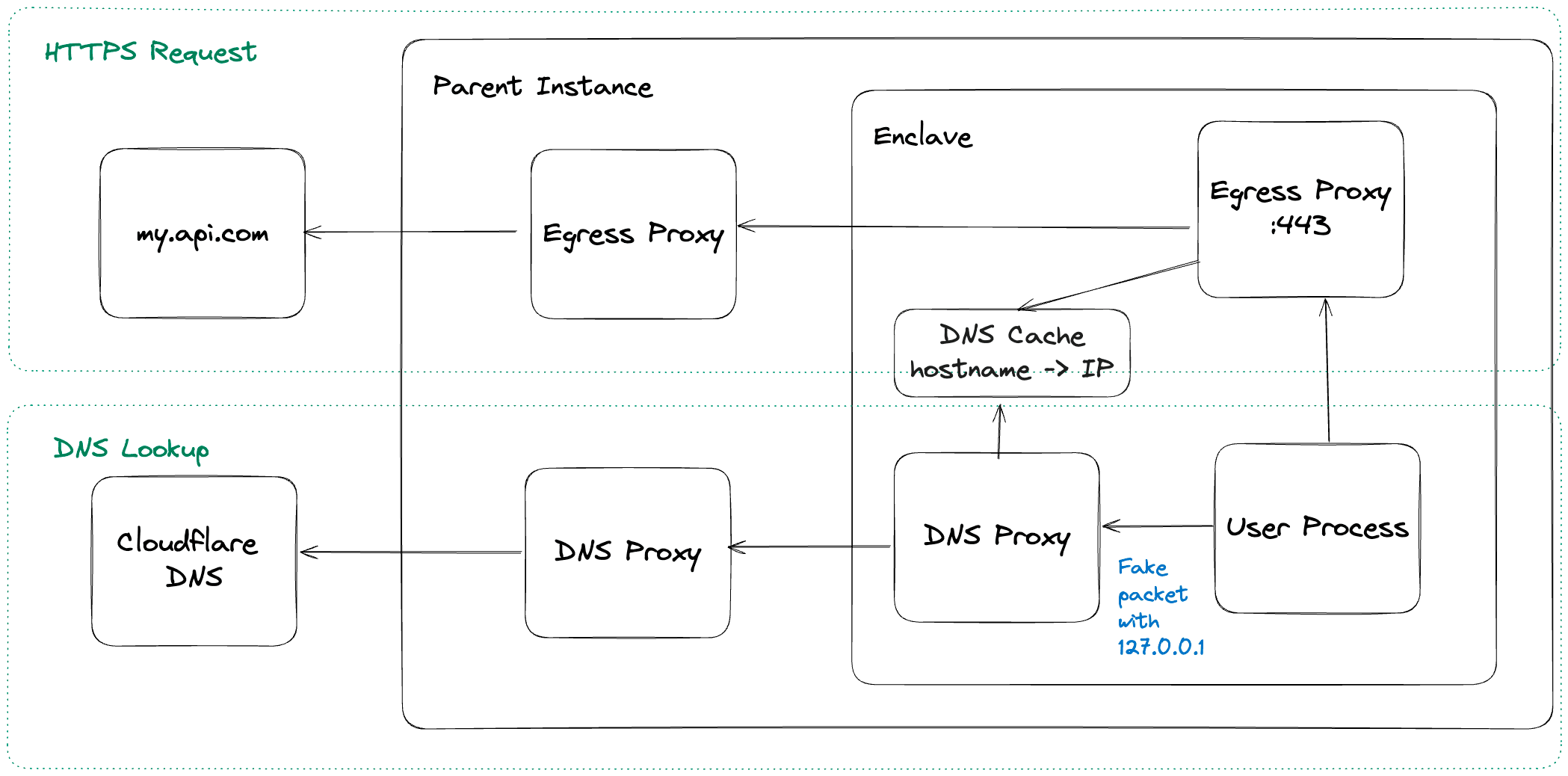
We created an on-Enclave DNS server that would intercept the request from the user process and proxy the request to a remote DNS server over VSOCK. It would then cache the DNS result, create a fake DNS packet with 127.0.0.1 as the address, and send that back to the user process.
The user code would then open a connection to 127.0.0.1:443, allowing the egress proxy to intercept the traffic. The egress proxy parsed the hostname from the initial bytes of the TLS request sent in plaintext in the SNI extension.
The initial bytes, along with the real IP and port, were then sent to the control plane, where the connection was made to the remote server, and the encrypted traffic was then blindly proxied from the remote host and the user process.
Users started to contact us with requests to allow egress on different ports; for example, SMTP typically uses port 587, so egress would fail because there was no listener on that port. We added a feature allowing users to specify what ports should be supported for egress, which would then start up a listener on each port. We knew this was not scalable, particularly when applications require egress on many non-standard ports.
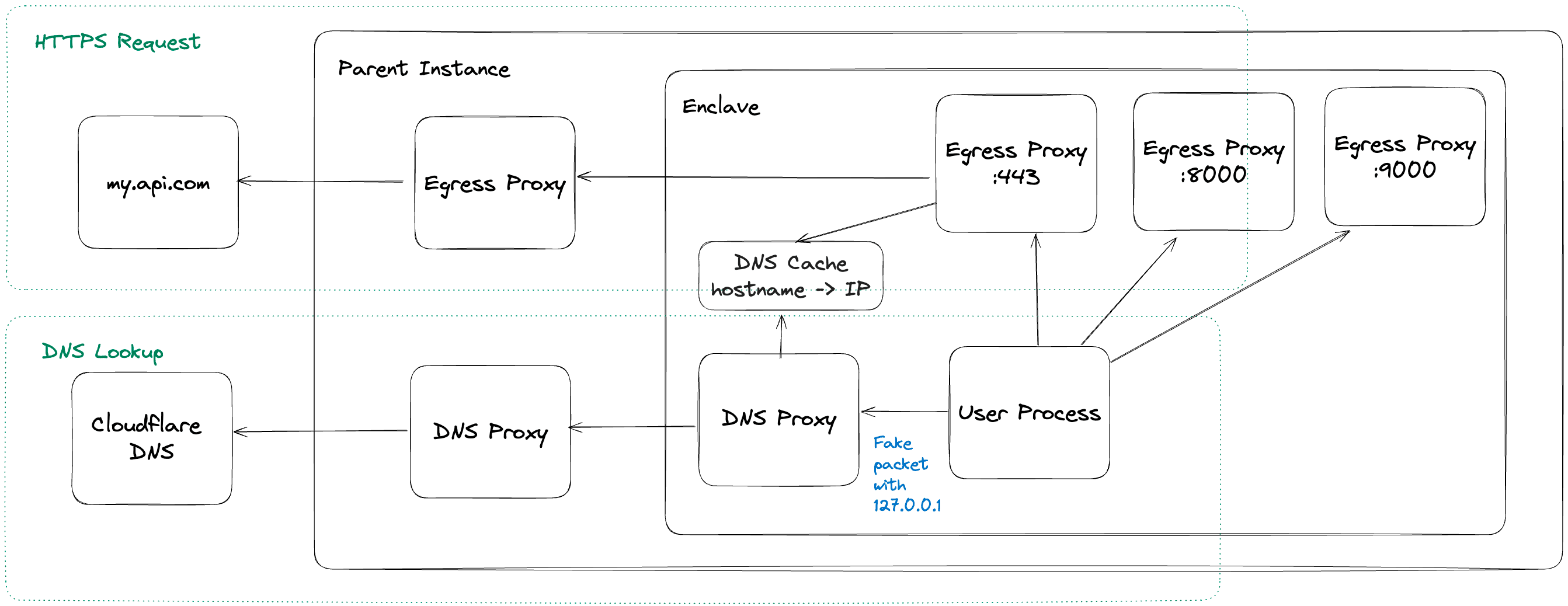
It was also confusing for users when they ran into issues, and they could see their DNS requests resolving to 127.0.0.1, resulting in time-wasting debugging issues.

This design also put a hard requirement on the egress traffic to be HTTPS. During the beta period, it became clear that users wanted the flexibility to use other protocols that may have an initial handshake before sending a Client Hello. We didn’t want to try to implement parsers for every possible protocol, so we decided to take another look at the network design.
We set aside some time before the Enclave GA release to improve or redesign areas of the product that weren't going to scale for a large number of use cases. We were keen to remove the need to bind to every port required for egress and unnecessarily waste Enclave resources.
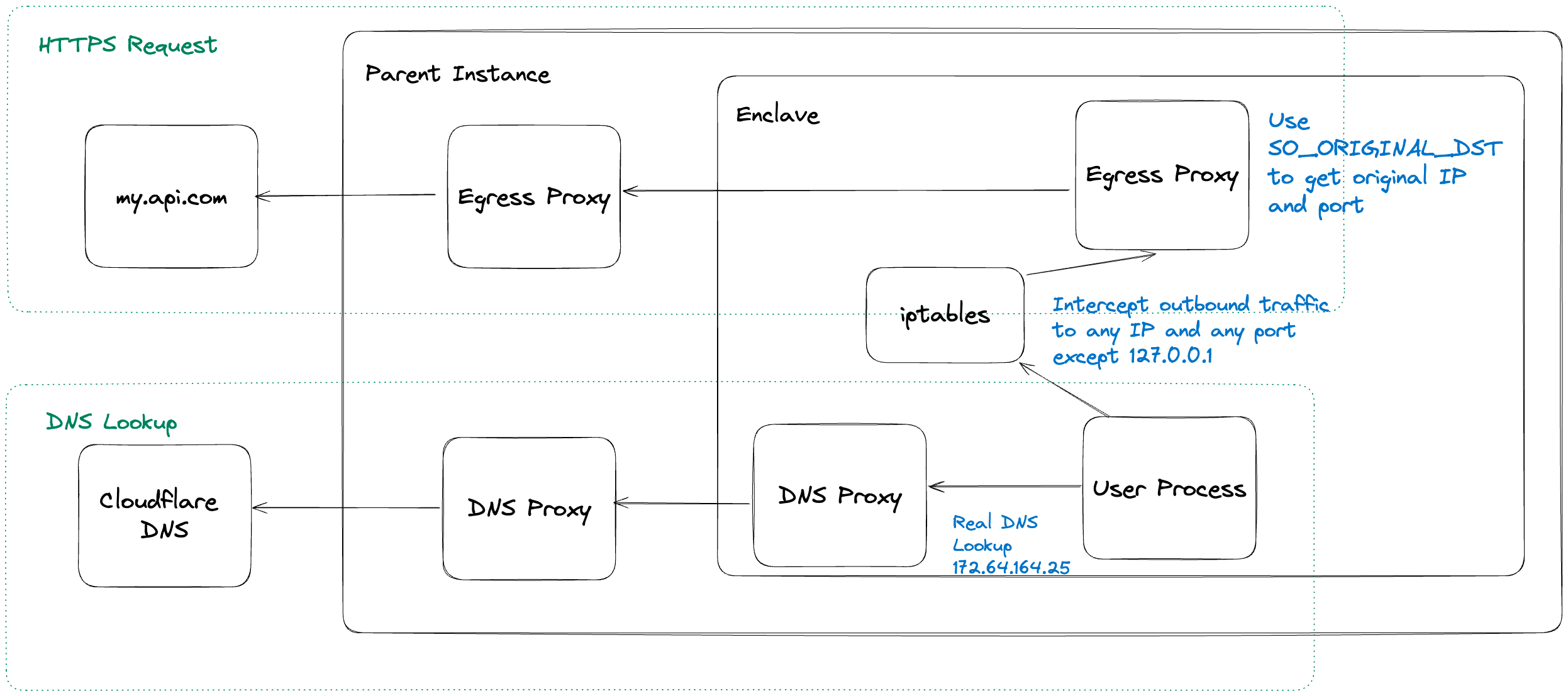
We needed a way to invisibly redirect the traffic from the user process to the egress proxy whilst maintaining the source IP so that reliance on SNI could be removed. This is where iptables come in handy. It's a user space program that filters incoming and outgoing packets on a given host and allows admins to apply rules that block or redirect traffic.
We could redirect traffic easily using the following rule:
1iptables -A OUTPUT -t nat -p tcp --dport 1:65535 ! -d 127.0.0.1 -j DNAT --to-destination 127.0.0.1:4444
2iptables -t nat -A POSTROUTING -o lo -s 0.0.0.0 -j SNAT --to-source 127.0.0.1This configuration filters outgoing packets on the host on any IP and port except loopback. We need to ignore loopback because the data plane talks to the user process on it, and redirecting that traffic would break the Enclave ingress networking. When the rule picks up outgoing traffic, it will redirect it to 127.0.0.1:4444, where the egress proxy is running.
The next issue we needed to solve was how to get the original destination address in the egress proxy. The destination address on the TCP stream appeared as 127.0.0.1:443 after redirection, which gave us no idea where to instruct the control plane to make the remote connection to.
We decided to look for projects with similar issues to see how they solved them. Cloudflare ran into a similar problem when building Spectrum and needed to accept traffic on 65k ports at a time without the overhead or binding to that many ports and proxy traffic while maintaining the original source IP.
They achieved this using the TPROXY module in iptables, which also maintains the source IP when the server has the IP_TRANSPARENT socket option set. This would mean the egress proxy could use the destination address on the TCP stream to determine the intended remote IP. Unfortunately, this only works on inbound traffic (on the PREROUTING chain), so it wasn’t suitable for our use case.
All was not lost, though, because iptables are used in popular service mechanisms like Linkerd for outgoing traffic. They rely on a socket option called SO_ORIGINAL_DST that is set when the traffic is proxied by iptables.
By using SO_ORIGINAL_DST to obtain the original IP and port, we can have a single egress proxy that facilitates TCP traffic destined for any IP and port.
Enabling network egress is optional, but we also want to ensure that users can explicitly specify the destinations that traffic from the Enclave should be allowed to reach. Setting an explicit list of egress domains removes the possibility of an Enclave falling victim to a supply chain attack.
Previously, we added domain allowlisting enforced inside and outside the Enclave. This was done by checking the SNI value against a list of domains configured by the user before deployment in enclave.toml. This was sufficient at the time because traffic could not leave the Enclave without the extension, so the domain would always be known.
As the new design does not constrain the egress protocols, it is now possible to send requests directly to IPs without any way of the egress proxy determining the hostname of the destination.
To account for this, we modified the egress proxy to check the IPs against the value in SO_ORIGINAL_DST. However, we didn’t want users to need to specify IPs for domains they don’t control that may have dynamic IPs. This would mean egress would fail if a third-party provider updated their IPs, and the only fix would be a new deployment.
Initially, it looked like iptables could solve this problem as it is possible to use hostnames in filter rules; however, the docs come with the following warning:
“Please note that specifying any name to be resolved with a remote query such as DNS is a really bad idea.”
An iptable rule set with a hostname won’t continue to refresh the IPs dynamically, so it wouldn’t help us solve this problem.
Instead, we decided that on each DNS lookup from the user process, we would block if the hostname being queried wasn’t an allowed domain. Then, any valid domain IPs would be cached with the DNS TTL so that the egress proxy has a fresh list of IP addresses to check against on each request out of the Enclave. This allows users to specify IPs and domains to secure their apps.
Using iptables, we simplified the egress networking and expanded the types of apps you can run in Enclaves. The main improvements are:
Get started today, simply create an Evervault account and start your free trial of Enclaves. Deploy and attest your first secure Enclave using three commands from the Evervault CLI.
Learn more
Secure your payment pages against script and security header attacks while complying with PCI DSS 4.0 requirements, 6.4.3, and 11.6.1.
Shane Curran
Multi-payment processor systems integrate multiple payment providers to handle transactions. Use Multi-psp to boost coverage to local populations and minimizes net transaction fees.
 Mathew Pregasen
Mathew Pregasen