- August 08, 2023
- 10 min read
Multi-party computation is (sort of) changing the game


Mathew Pregasen
Content Contributor
With the exception of blockchain, most “cutting-edge” computer science techniques had their origins in the ‘80s. One of these is multi-party computation.
Multi-party computation (MPC) is not a specific thing, but a category of algorithms that perform computations on private data across multiple devices. The main tenet of multi-party computation is that the device data stays private. MPC anonymously accomplishes this with a dash of mathematical magic.
MPC has generated a bit of buzz lately, and it makes sense. We live in a time where privacy is every other coder’s favorite topic. MPC delivers a “best of both worlds” promise, working with data without directly accessing it. But it’s just buzz so far. At this point, MPC isn’t flourishing in the real world; most implementations are in a rather early stage.
Today, I am going to try to understand this discrepancy. Specifically, I want to understand why MPC hasn’t seen mass adoption despite the tons of press discussing it. I’ll begin with some background on how MPC works and then journey into how that fits with today’s problems.
But first, a quick anecdote.
A tale of Danes and sugar beets
In 2008, the first production implementation of multi-party computation was used during the Danish Sugar Beet Auction. Danish farmers wanted to keep their bids for production contracts anonymous. There was fear that public bids would reveal each farm’s productivity, which contract sellers would use to their advantage.
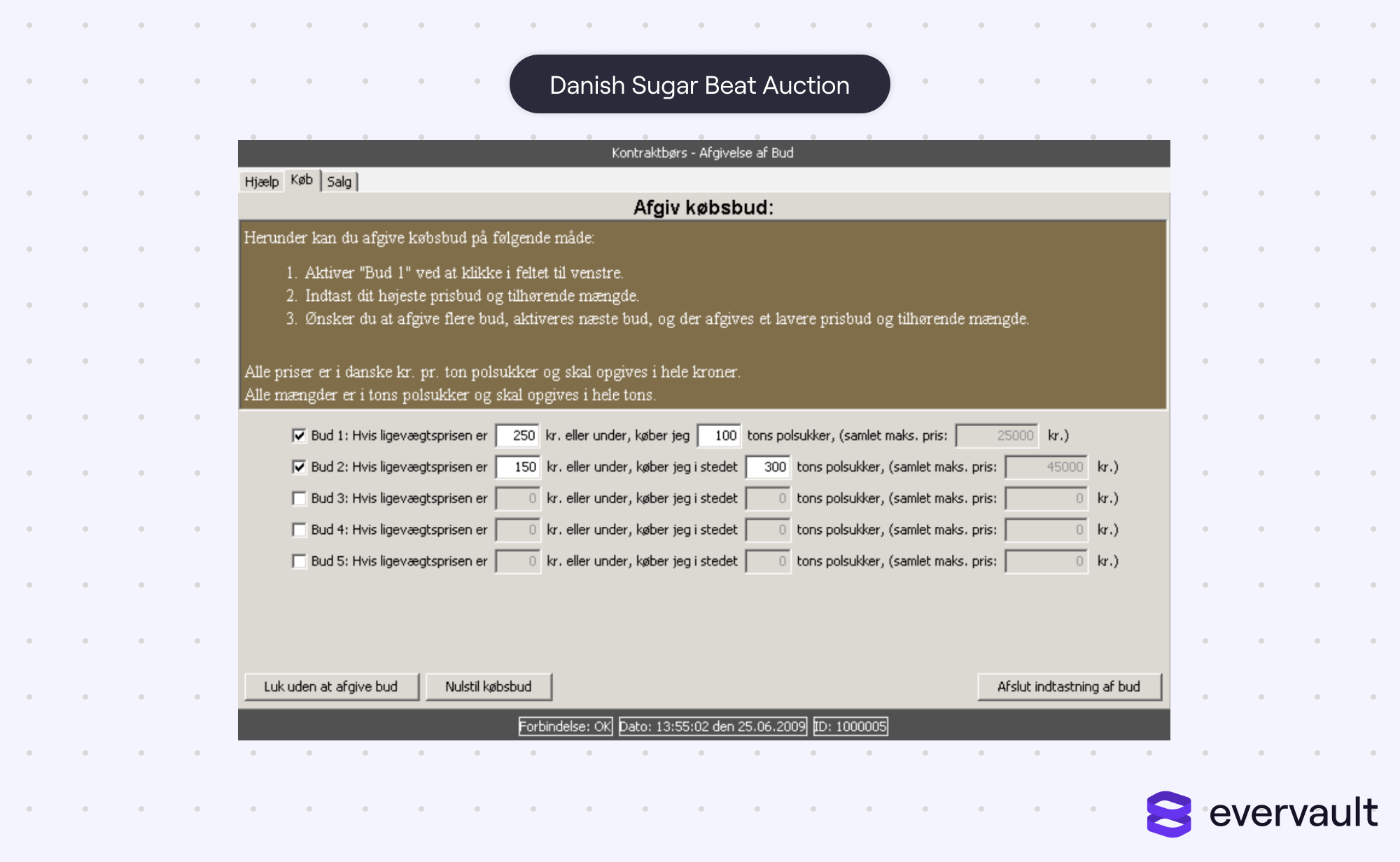
By using multi-party computation, contracts were efficiently matched between sellers and buyers without revealing the exact bids for each. It was the first successful implementation of multi-party computation in the real world. The Danish Sugar Beet auction! The name alone sounds like a Wes Anderson movie, but hey, it’s history.
How multi-party computation (MPC) works
A tricky component of multi-party computation is that accomplishing different mathematical functions requires very different algorithms. They might use some similar tactics—namely oblivious transfer and bitwise XOR—but generally speaking, they are quite distinct.
A simple MPC problem
Let’s drive through a simple MPC algorithm. Imagine that Tina, Tasha, and Tahmid want to learn the sum of their salaries without sharing their salaries explicitly. In this scenario:
- Tina makes $200 per week
- Tasha makes $300 per week
- Tahmid makes $250 per week
Typically, this would be done by a trusted intermediary. But imagine if a trusted intermediary didn’t exist. That’s where MPC shines—with it, the sum can be calculated without Tina, Tasha, or Tahmid learning each other’s salaries.
The algorithm is very straightforward:
- First, each person needs to split their salary into three random components that add up to their salary. Negative numbers are allowed, allowing an infinite set of possibilities. For instance, Tina could break her $200 salary into $130, $400, and -$330.
- Each person distributes a different component to the others, keeping one for themselves (e.g., Tina shares $400 with Tasha and -$330 with Tahmid, keeping $130 for herself).
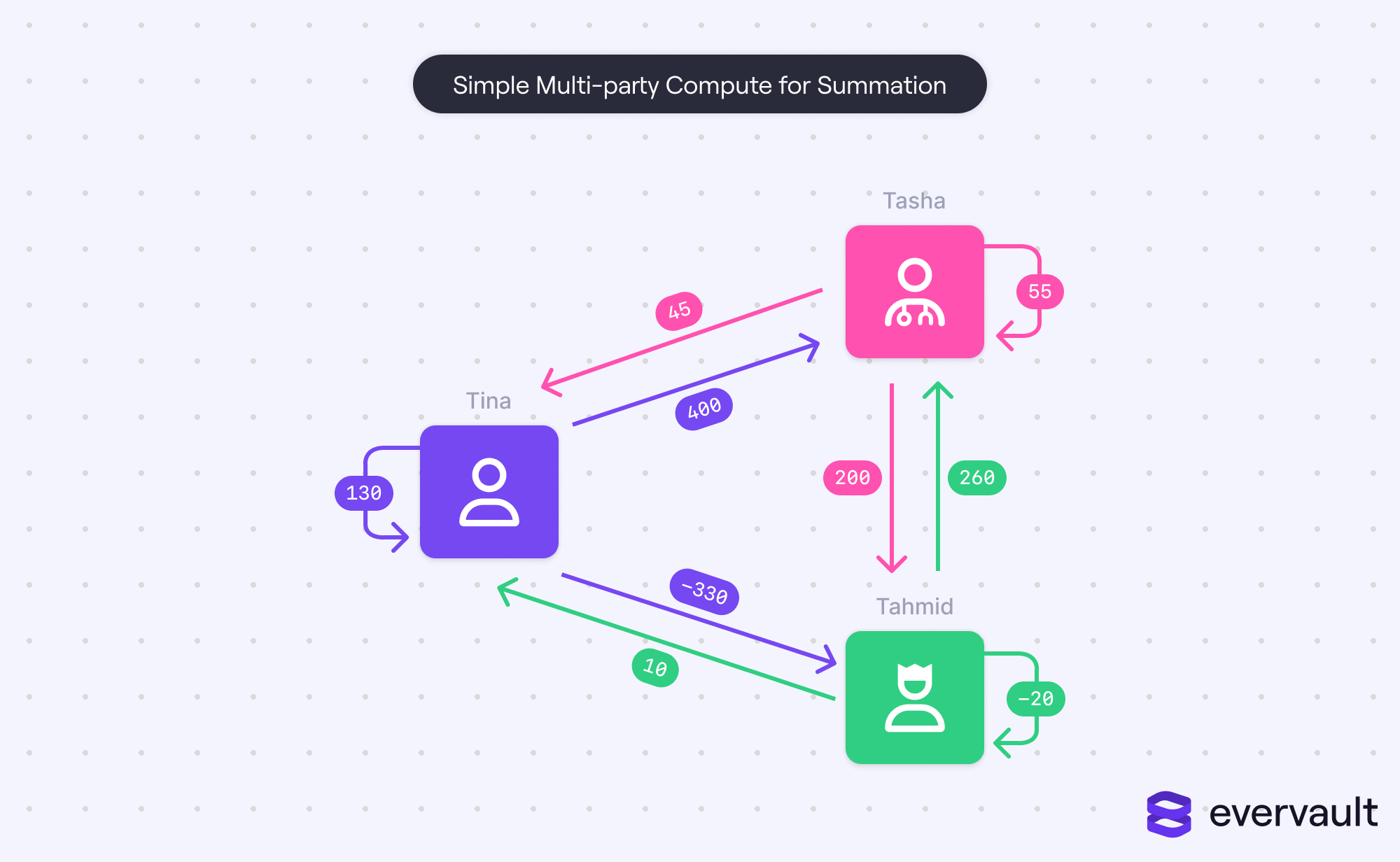
- Each person sums all of their components, including their own component that they kept.
- Finally, everyone shares their sums with the other users. Each user adds the other users’ sums to their own, calculating the total sum.
That’s it. In this scenario, receiving a component doesn’t hint at the user’s real number. This becomes obvious when you consider the extremes. Getting $100,000,000,000 from a user doesn’t mean that they are pre-Twitter Elon Musk! They could’ve shared -$99,999,999,900 with another user, and kept a component of $0 for themselves, resulting in a $100 salary.
The crux of MPC is that the “third user” renders any data shared with the second user useless (outside of calculating a joint computation).
What happens if there are two users?
Believe it or not, it’s still possible to calculate (some) values between just two users! One of the most famous was Yao’s millionaires’ problem, in which two millionaires want to determine who is richer without revealing their actual salaries. This is more complicated, however, as it requires a mix of oblivious transfer and bitwise XOR.
Of course, the list of two-party computation problems is small. Some math functions are inherently reversible when only two values are involved. For instance, even if two millionaires could average their salaries using an MPC technique, they would still be able to reverse-calculate the other’s salary from the solution afterward.
Enter FairplayMP
One complicated thing about MPC algorithms is they rely on bitwise XOR and AND. While modern languages can definitely compute bitwise XOR, it is computationally expensive at scale. Technically, MPC systems would be most efficient with custom circuits of AND and XOR gates for specific functions; however, in today’s world, that is impractical. We tend to just toss more software at a problem to make it work with generalized architecture and languages.
That’s what FairplayMP did for MPC. FairplayMP is a system that efficiently compiles an MPC function into a Boolean circuit. With FairplayMP, devices can arbitrarily perform MPC algorithms by just sharing a function file and configuration file.
What if a party lies?
If a party lies, MPC breaks. Multi-party computation relies on parties being semi-honest—they’ll follow the given instructions honestly, but they should not be trusted with the other parties’ data. In the previous summation problem, if any person lies about their salary, then the computed sum is going to be wrong. And that’s fine. Multi-party computation isn’t meant to verify that a party acted honestly but to enable them to work together without explicit data sharing.
Why multi-party computation is still in its infancy
Despite hitting the developer limelight in the last decade, multi-party computation has barely seen adoption. Yes, it was used for the Danish Sugar Beet Auction, something that would make Dwight Schrute proud. It’s also been used for evaluating pay disparities or detecting tax fraud, but these uses of MPC were both niche and experimental. They exist at a small scale relative to commercial applications.
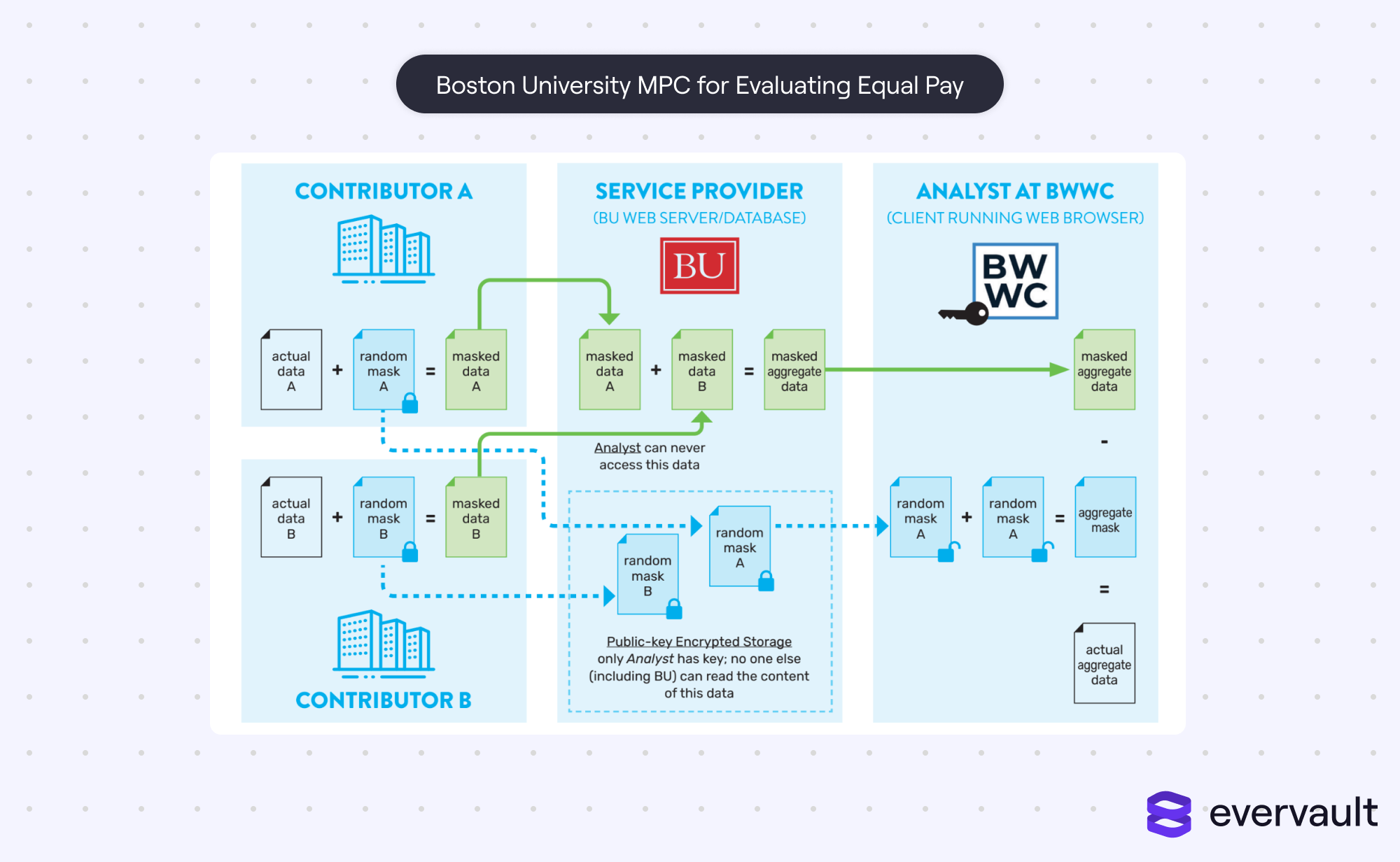
This MPC variant uses a centralized server to collect results, but the server cannot decrypt the data. Fundamentally, this follows the same premises of MPC.
Why are MPC’s implementations still so rudimentary when it’s been a decade and a half since the Danish Sugar Beet Auction? To understand why, let’s discuss the two types of (hypothetical) MPC applications.
MPC for client data
Given that devices, especially mobile devices, are saving data on a minute-by-minute basis, there’s ample opportunity for MPC to improve applications.
Of course, MPC is irrelevant whenever a device requires a centralized service to save plaintext data on the cloud. This tends to be the case with many space-conscious applications. Granted, the data could be saved in an encrypted form, in which case there’s an argument for MPC for joint operations.
MPC for corporate data sharing
Another opportunity for MPC is in data sharing among corporations. Due to Europe’s GDPR and California’s CCPA, corporations (for good reason) have to disclose whenever they share data with third parties. Even if corporations trust each other, this makes a case for using MPC if they ever want to jointly compute their data without actually sharing it.
Imagine if three banks want to calculate the average spend of certain vendors to build better fraud models. Even if data was shared anonymously without any attached PII, it opens doors for profiles to be reverse-engineered since financial data could be matched with other factors (like geographic data, demographics, etc.). MPC addresses that issue head-on.
But these are just hypotheticals
There are a few headwinds against MPC’s adoption.
Path of least resistance
The greatest problem is that MPC is rarely the path of least resistance from the developer’s standpoint. Now, it’s not that developers want to invade people’s privacy willy-nilly. Rather, it’s because the general choice often reduces to “Is it easier to use a centralized server and pay our lawyers to draft some privacy agreements?” Usually, the answer is yes.
Why? For starters, MPC is hard to implement. Given that the data remains private, it’s tough to debug. Additionally, MPC needs to be tolerant whenever devices turn unreliable.
So, instead, some “military-grade encryption” marketing mixed with some privacy policy amendments tends to be the path of least resistance.
Inevitable data collection
Another issue with MPC is that it’s often incompatible with an application’s business model or data system. Nowadays, applications don’t typically rely on local data. Data sync support across devices has become a table-stakes requirement; even grocery list apps or baby monitors use the cloud to sync user data. Applications could hypothetically use a local value (like a password) to reversibly encrypt data without storing the key itself, but this strategy is primarily suitable for applications that need to prioritize privacy over convenience (e.g., password managers).
I am making two exceptions
I sort of lied when I said MPC has had lackluster success. There are two places where MPC has actually achieved large-scale implementation, but they don’t exactly “count” for two widely different reasons.
Blockchain
Any crypto developer might be miffed at the lack of blockchain mentions. After all, many blockchain applications use multi-party computation (or some flavor of it) for performing functions across a blockchain app. And if you were to Google “multi-party computation”, a lot of blog content with SEO share is published on blockchain blogs.
However, MPC is just a facet of how blockchain works. Conditioning MPC’s viability in the context of blockchain is more a matter of blockchain’s long-term viability, not MPC’s. It’s just more interesting to discuss whether MPC has potential outside of crypto.
PSI and passwords
Private set intersection (PSI) is a unique multi-party computation algorithm in which two sets can be compared for any intersections without sharing the set data itself. The real-world application of this, which has been implemented by Apple, is password checks.
Apple and other applications don’t want to share user passwords with leaked password services. It creates a new surface for attackers to exploit; in general, the idea of sharing passwords plaintext with a centralized service is rotten. Thankfully, private set intersection allows for passwords to be compared without the passwords themselves being shared.
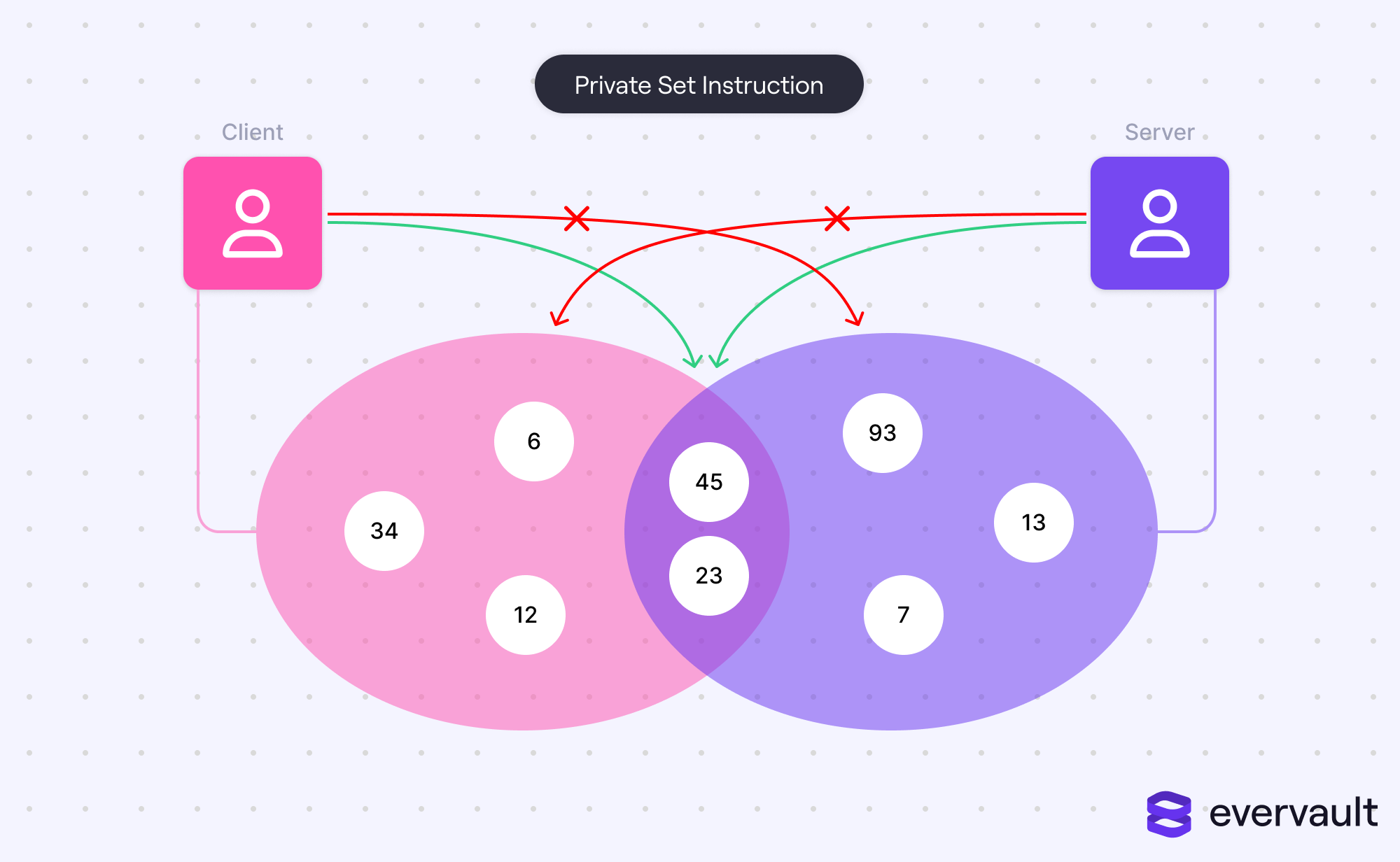
Without a doubt, this is a huge application of multi-party computation. However, private set intersection is quite distinct from other MPC problems. It doesn’t require values to actually be computed, only compared. Additionally, it allows for techniques like irreversible encryption (e.g., hashing) because determining equivalence is a significantly easier problem.
Closing thoughts
In theory, multi-party computation has a lot of potential. It could make so many processes privacy-friendly without compromising analytical or even transactional needs. Multi-party computation is up against some major headwinds, though. In today’s world, multi-party computation is rarely the path of least resistance.
Regardless, the success of multi-party computation for certain niche applications means it’s not totally impractical. It could have a bright future, even if the long-term success is limited by the nature of how modern applications are built.
